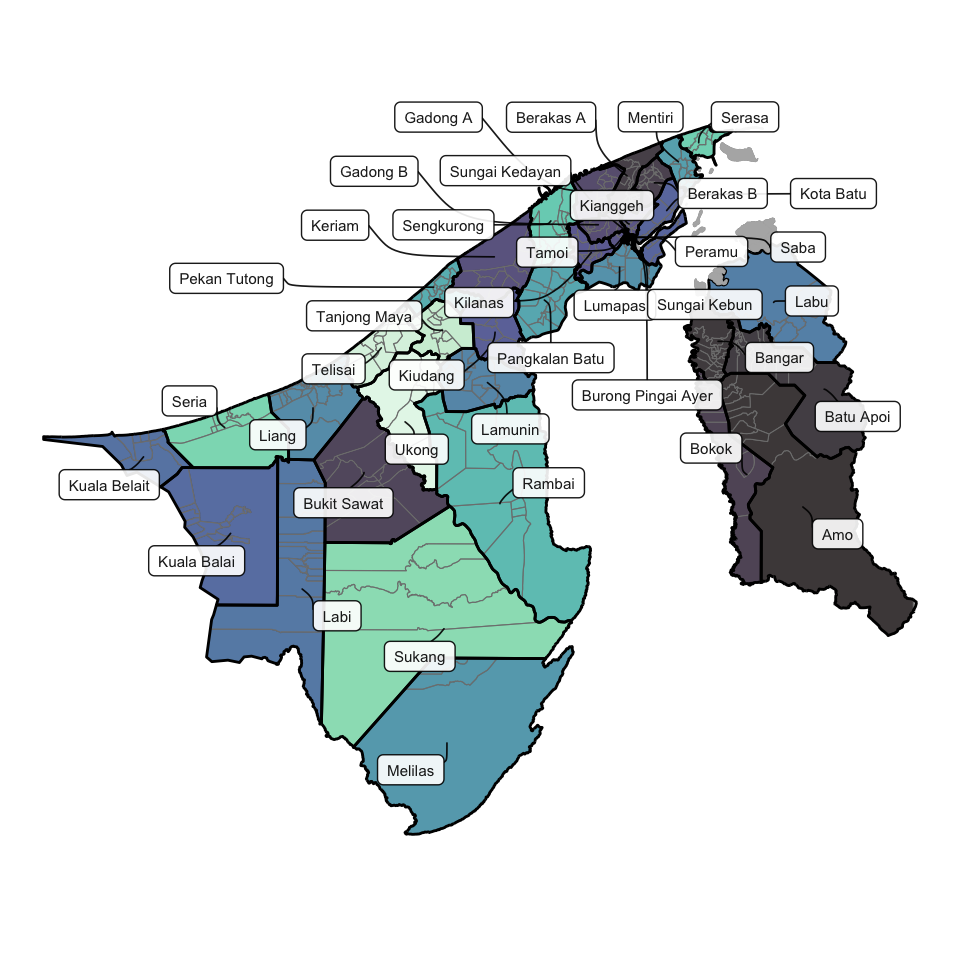
[1] "Hello, World!"[1] 3[1] 1
[1] 2
[1] 3
[1] 4
[1] 5AITI Talk

Assistant Professor in Statistics, Universiti Brunei Darussalam
Visiting Fellow, London School of Economics and Political Science
May 21, 2025

Instructions and material available at https://haziqj.ml/ aiti-talk/
| Time | Activity |
|---|---|
| 0830 – 0900 | Introduction & Getting Started with R |
| 0900 – 1000 | Lecture 1: Basic Statistics |
| 1000 – 1030 | Break |
| 1030 – 1130 | Lecture 2: Advanced R stuff |
| 1130 – 1200 | Networking |

slido.com code: 3244786
 Datasaurus supports you!
Datasaurus supports you!
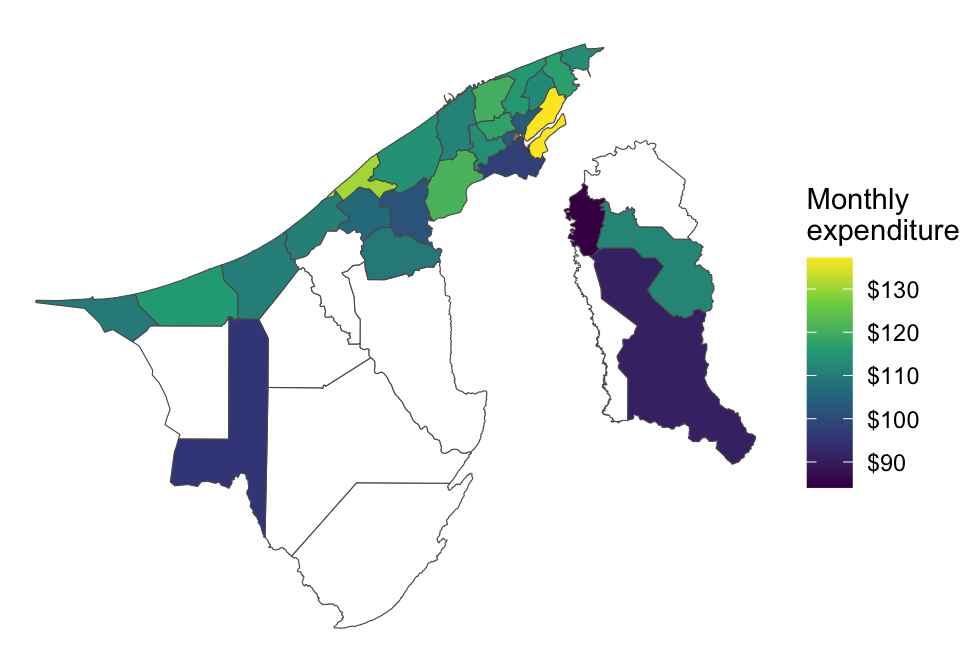
Automate End-to-End Survey Processing
Write one script that pulls raw survey responses, cleans and validates fields and outputs ready-to-analyse datasets.
Standardise Analysis & Quality Checks
Embed your business rules into reusable code so every round adheres to the same quality standards.
Generate Dynamic Reports in Seconds
Turn your cleaned data into up-to-date charts, tables and written summaries automatically.
Quickly Prototype “What-If” Scenarios
Simulate alternative weighting schemes, forecast adoption trends or run sensitivity analyses on key ICT indicators to guide policy adjustments.
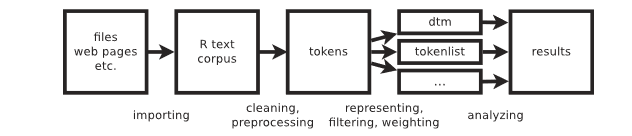
R is an interpreted programming language for statistical computing and data visualisation. It has been adopted in many fields, especially quantitive fields like data science.

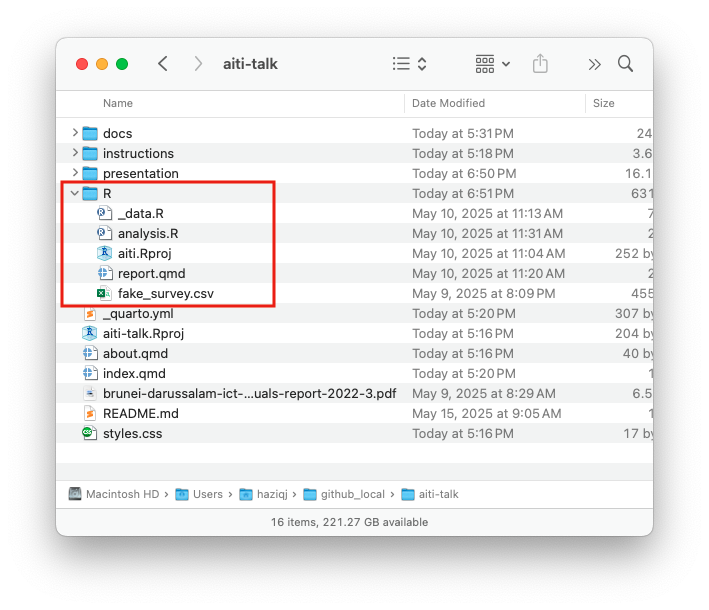
aiti.RProj fileProject folder
R needs to know where is your project’s “home” directory. By clicking on the RProj file, RStudio will set the working directory to the project folder.
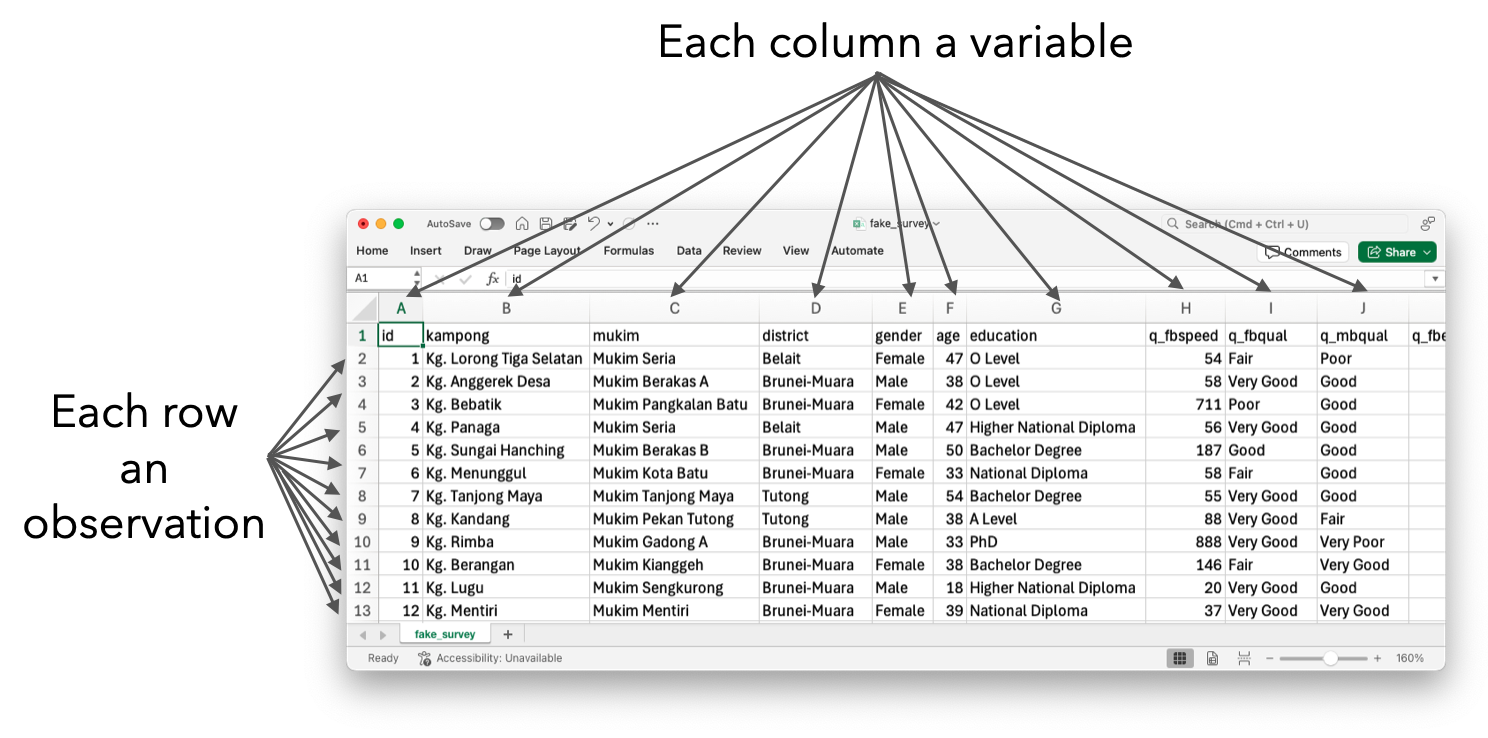
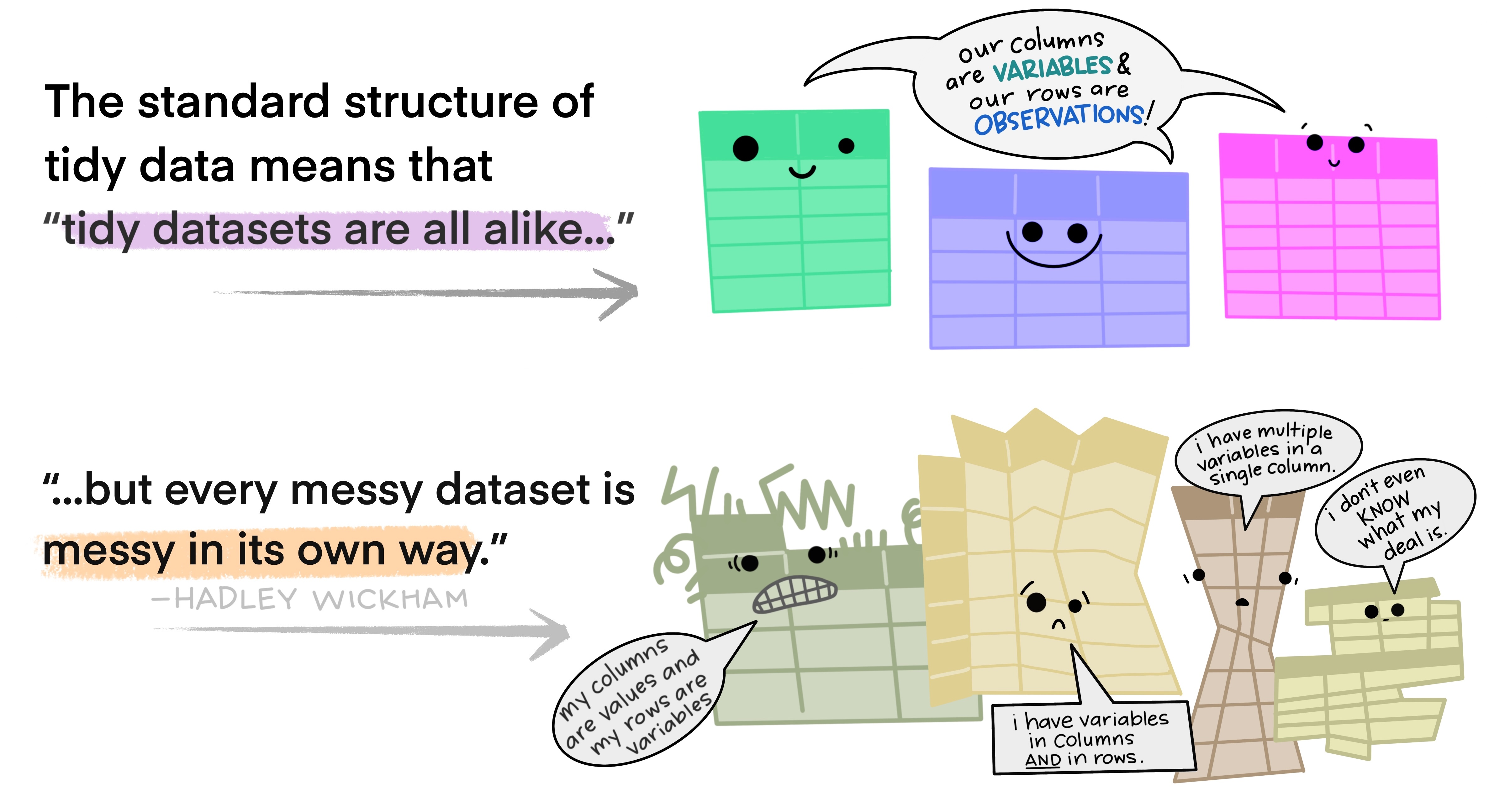
All happy families are alike; each unhappy family is unhappy in its own way. —Leo Tolstoy
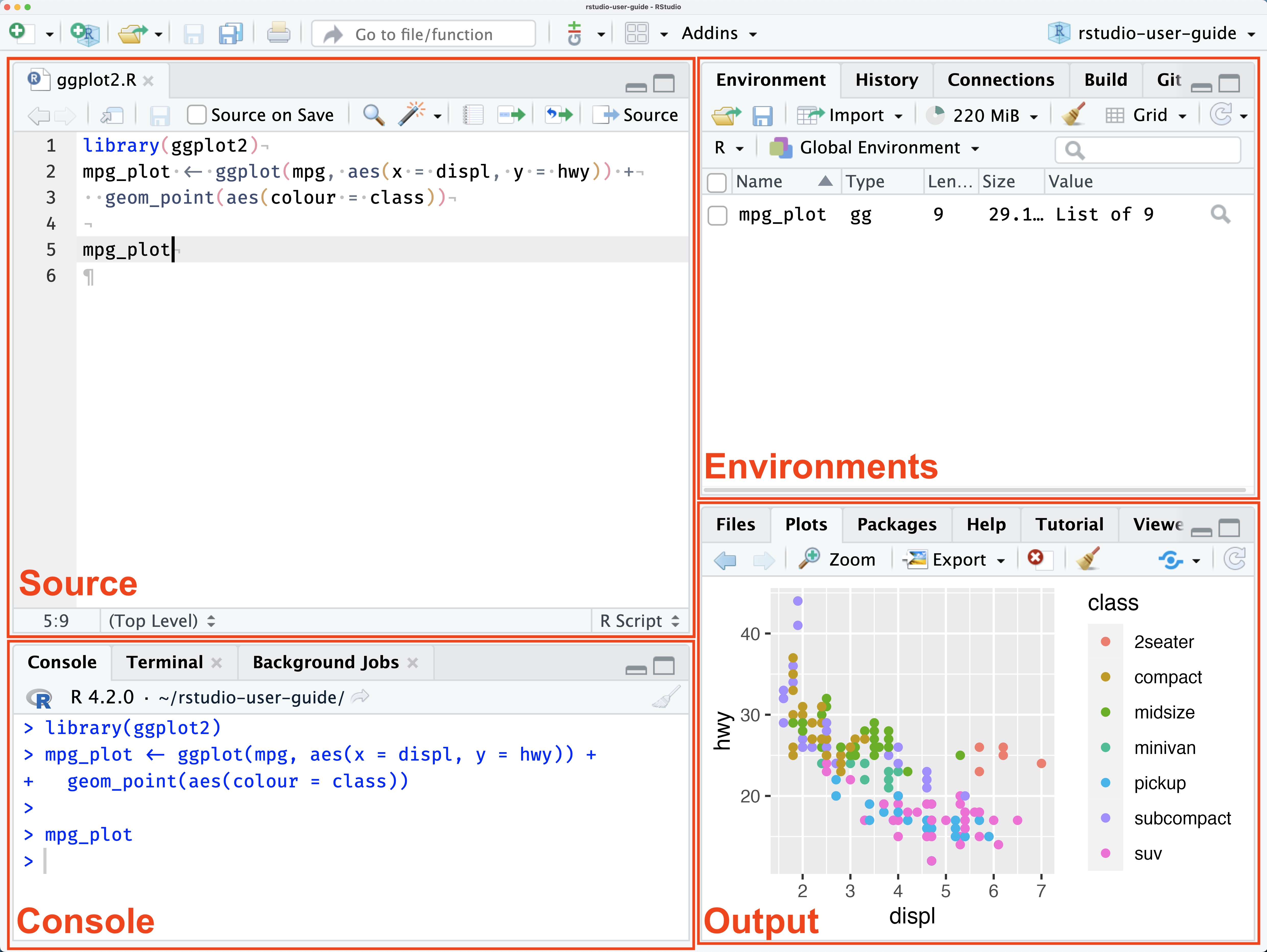
Emphasis on writing reproducible R code
Appreciate that there’s a leaRning curve
Goal of the talk is to show what R is capable of

At its core, statistics is the science of understanding variability.
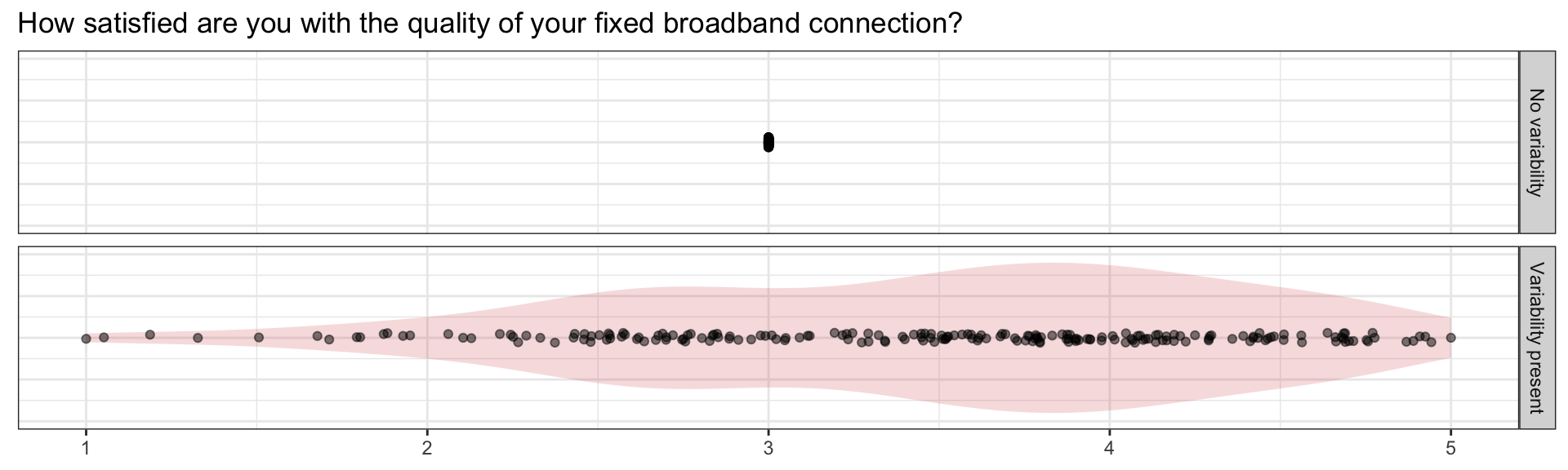



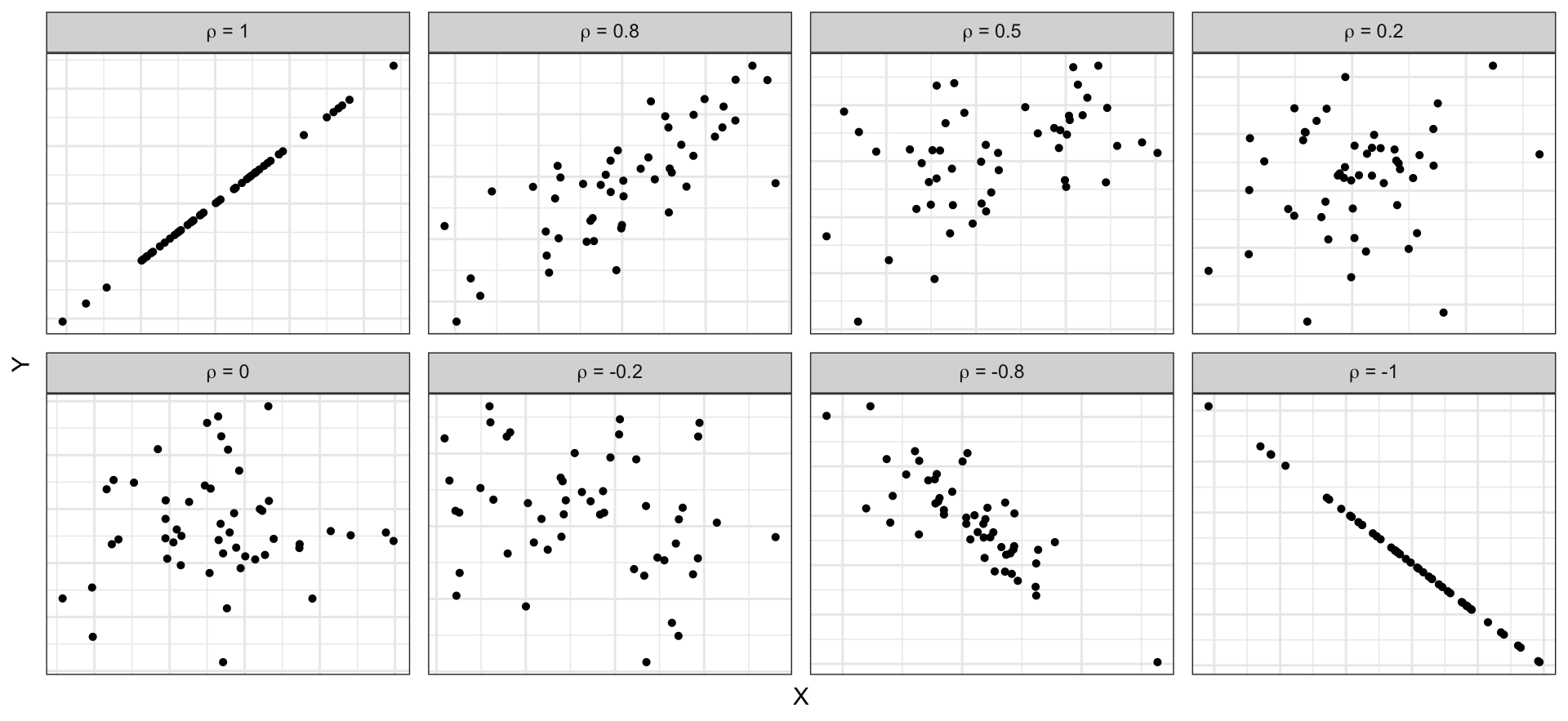
\[ \rho = \frac{\text{Cov(X,Y)}}{\text{SD(X)}\times\text{SD(Y)}} \in [-1,1] \]
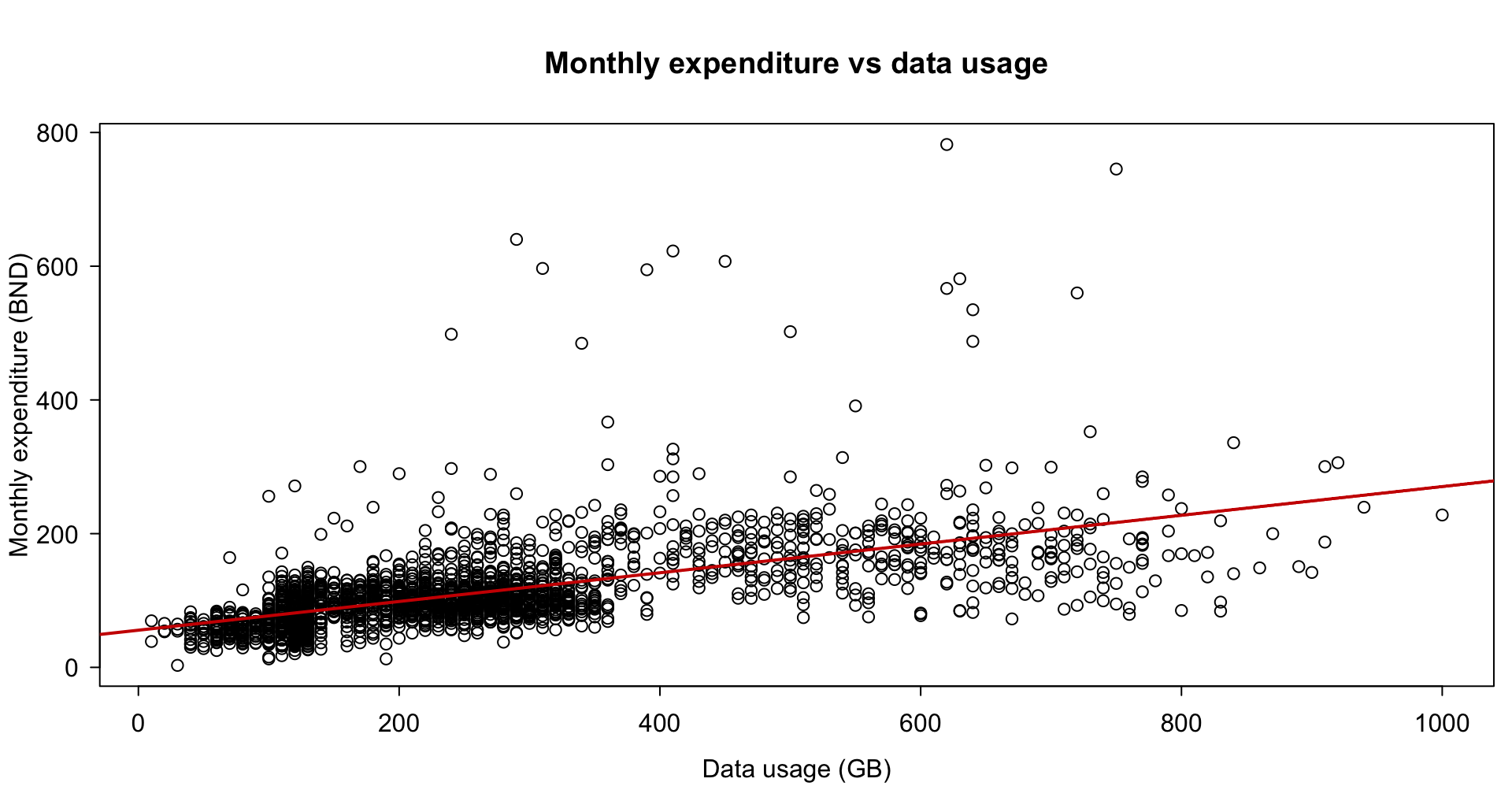
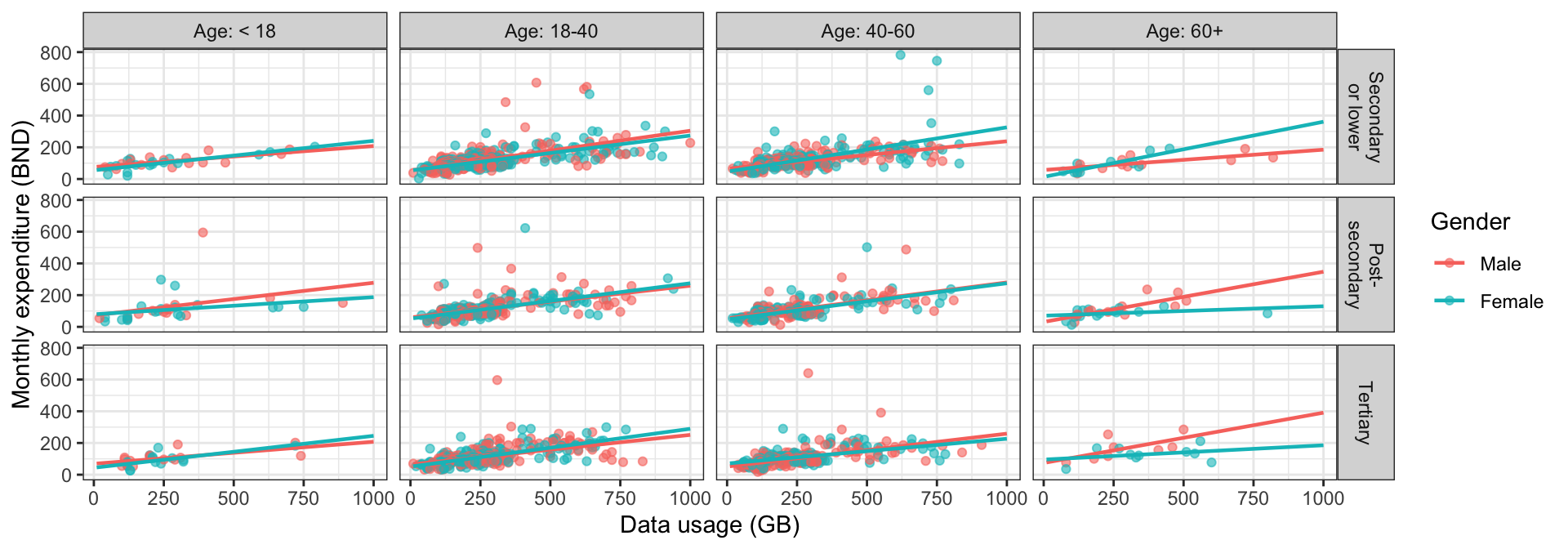
dat$gender: Male
Min. 1st Qu. Median Mean 3rd Qu. Max.
12.65 79.26 101.46 114.92 133.07 640.10
------------------------------------------------------------
dat$gender: Female
Min. 1st Qu. Median Mean 3rd Qu. Max.
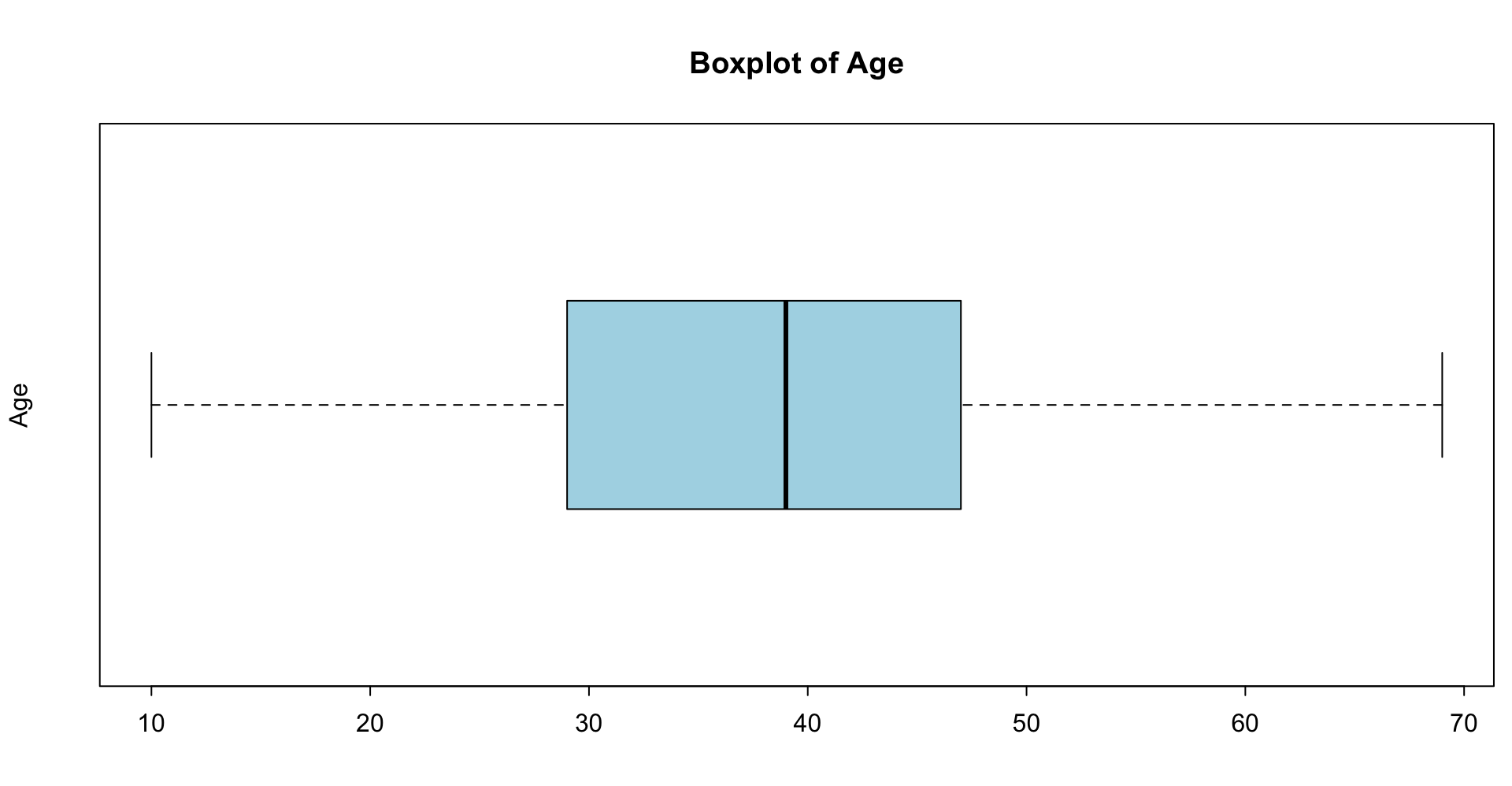
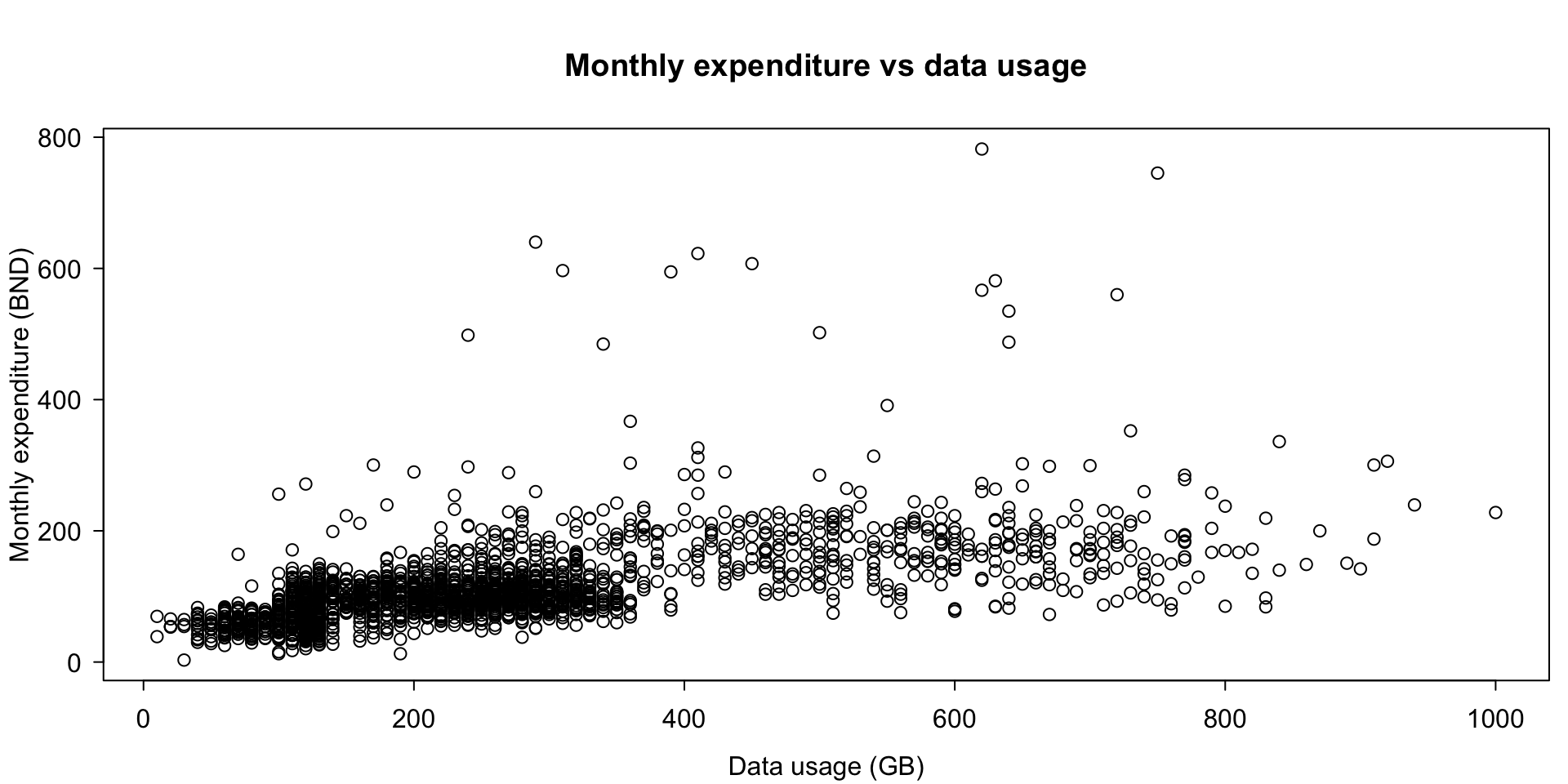
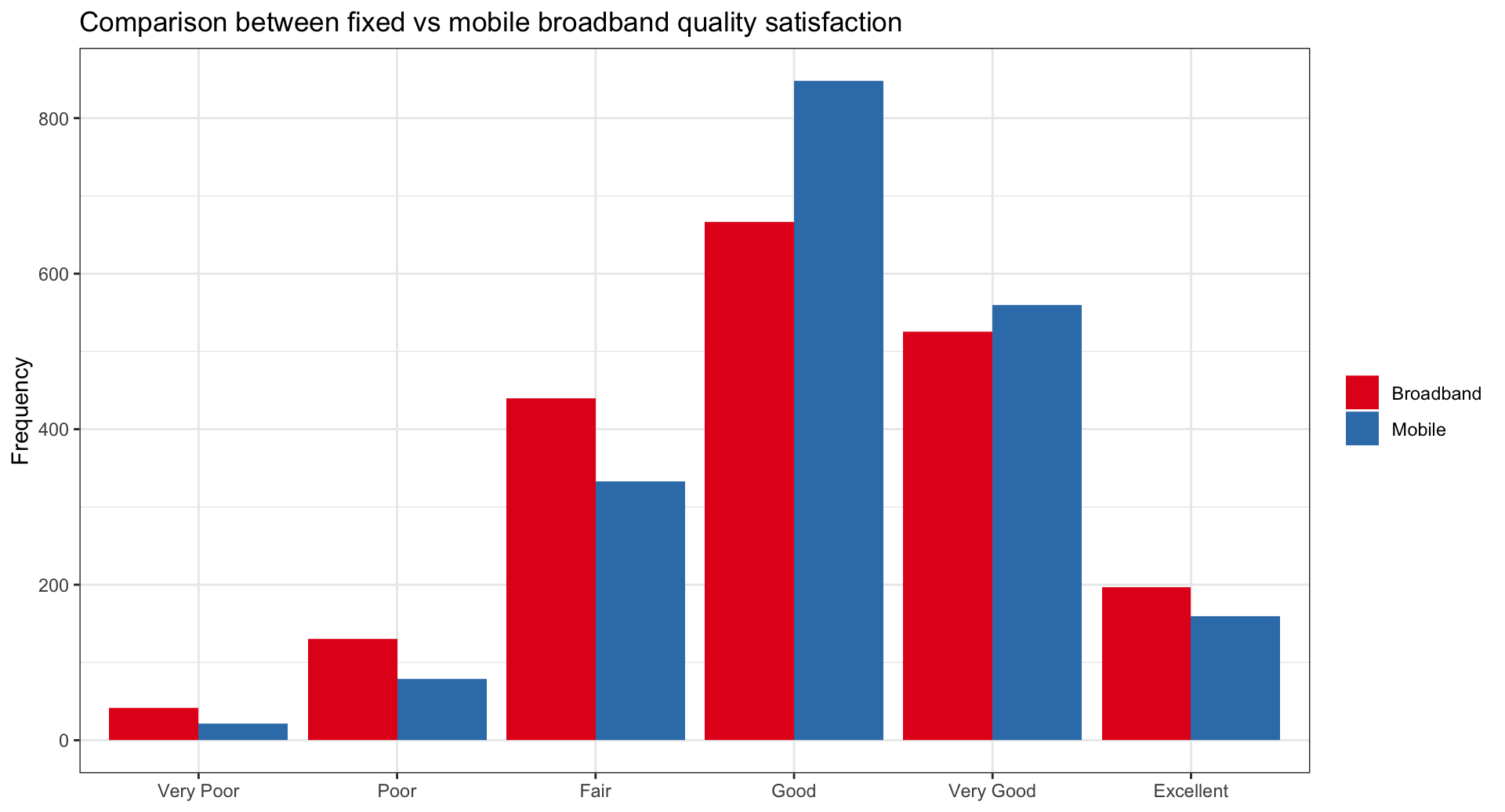
3.00 76.36 99.53 113.27 130.42 782.00 boxplot(q_fbexpend ~ gender, dat, range = 5, col = "lightblue", horizontal = TRUE,
ylab = NULL, xlab = NULL, main = "Monthly expenditure (BND)")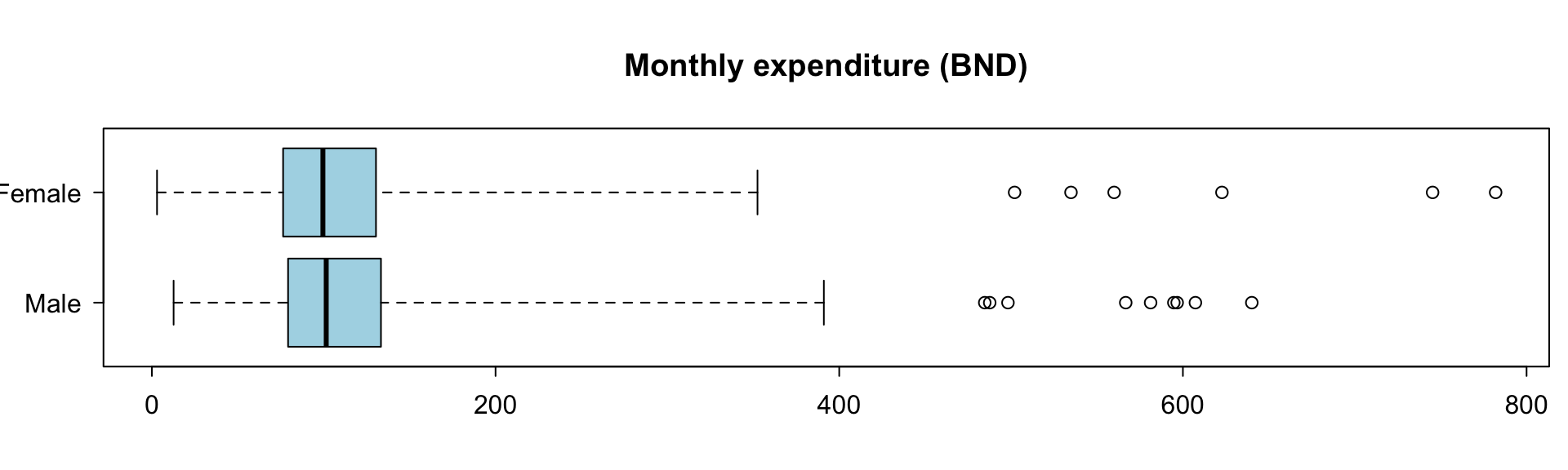
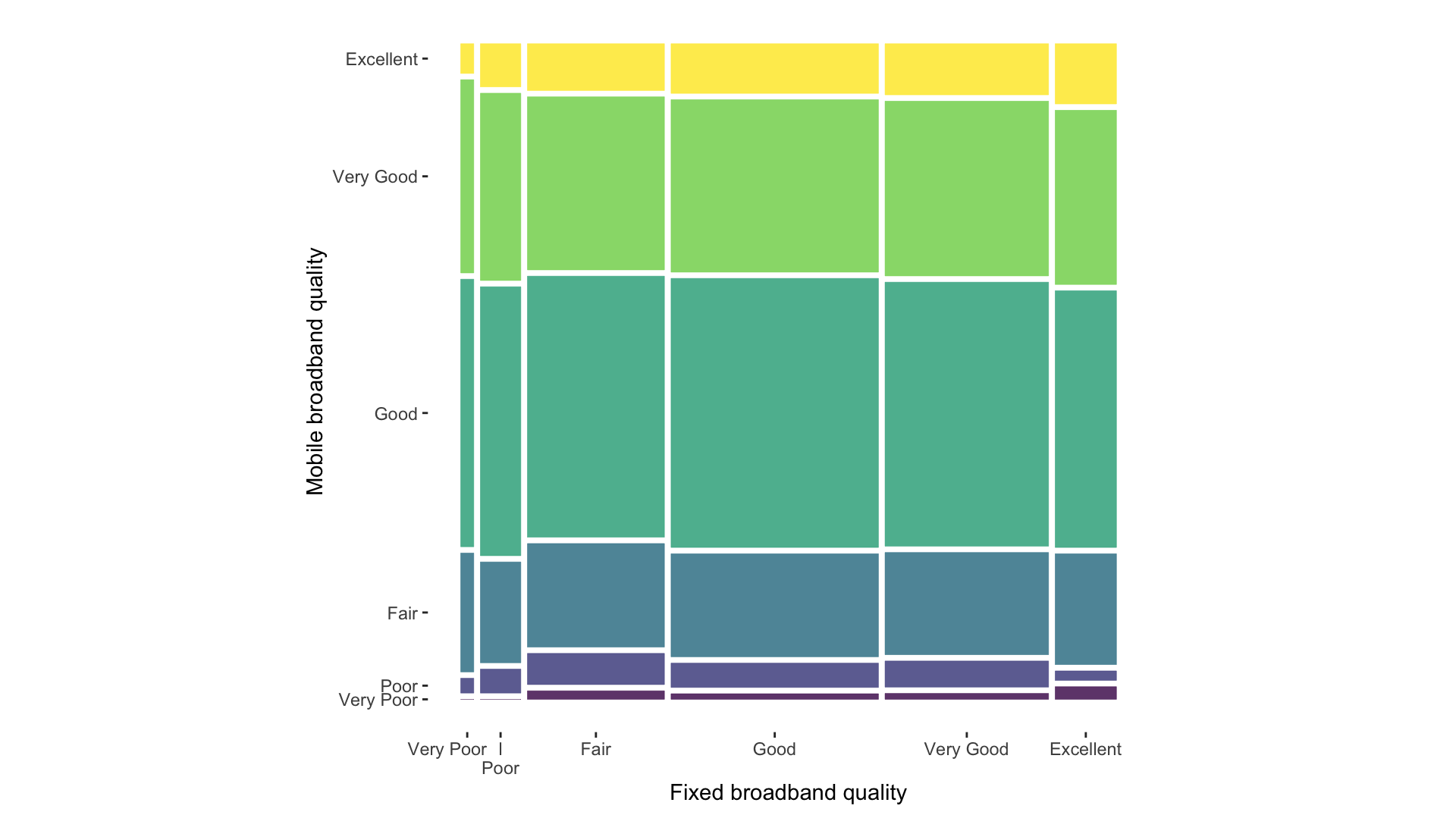
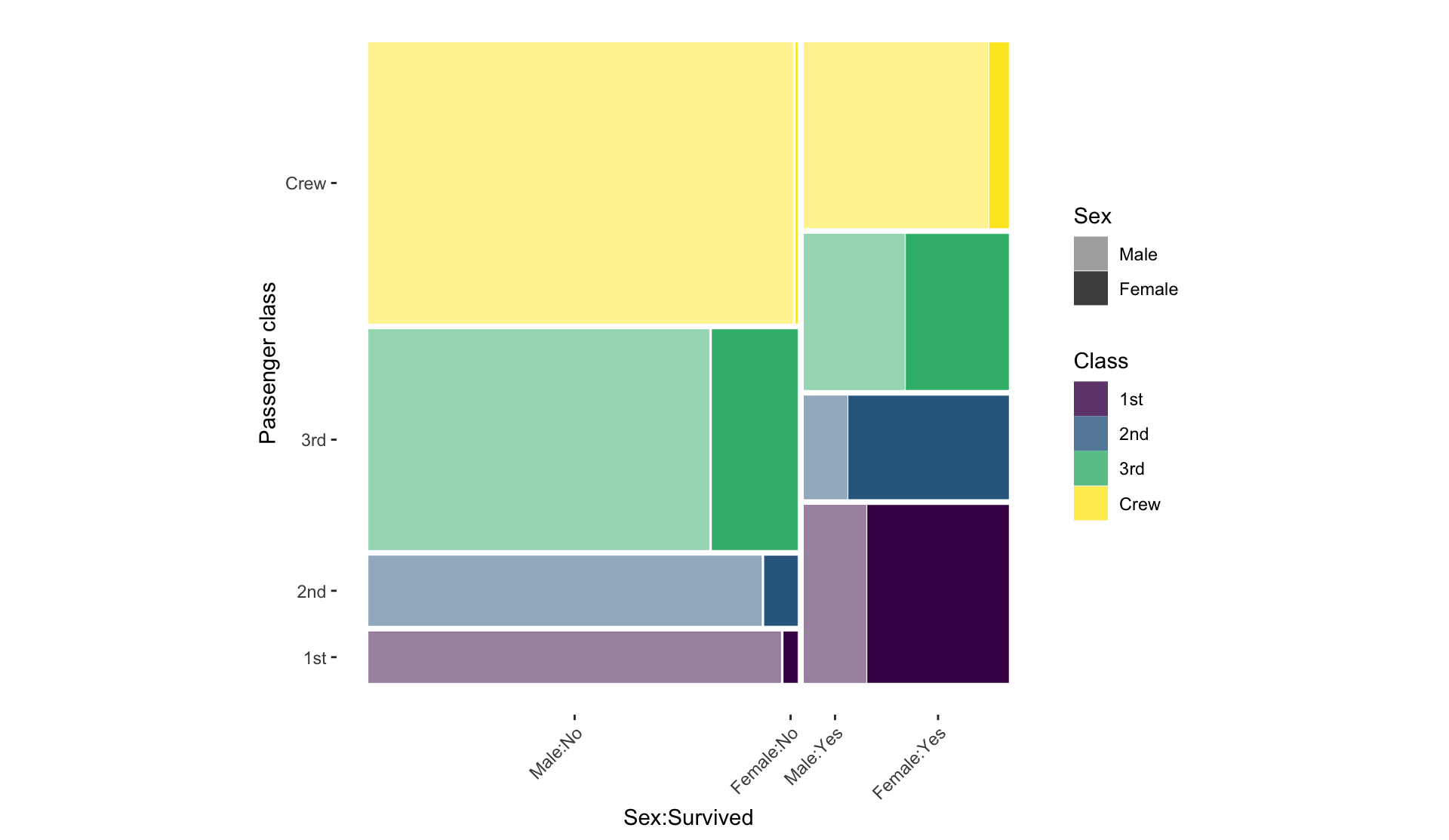
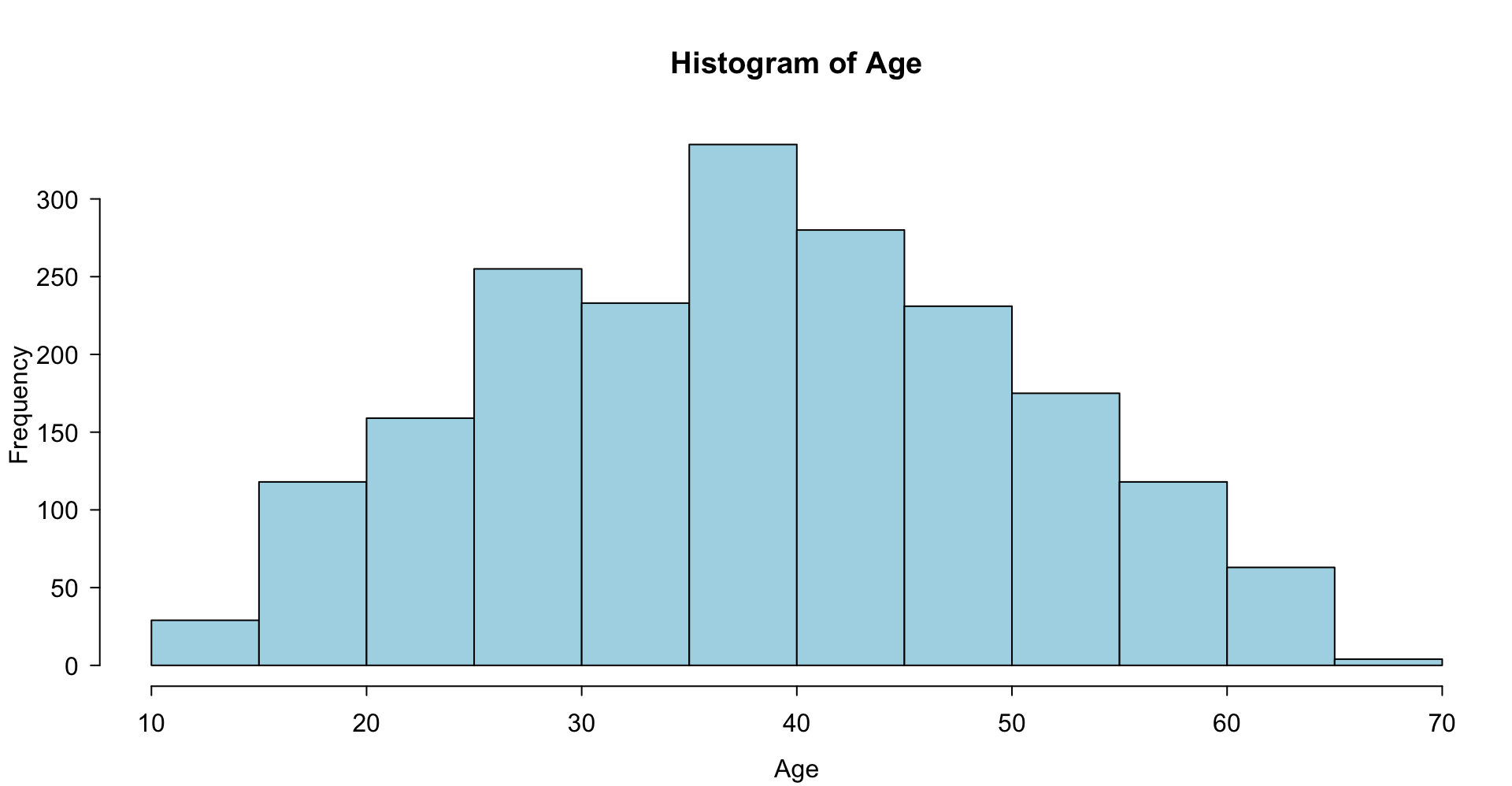
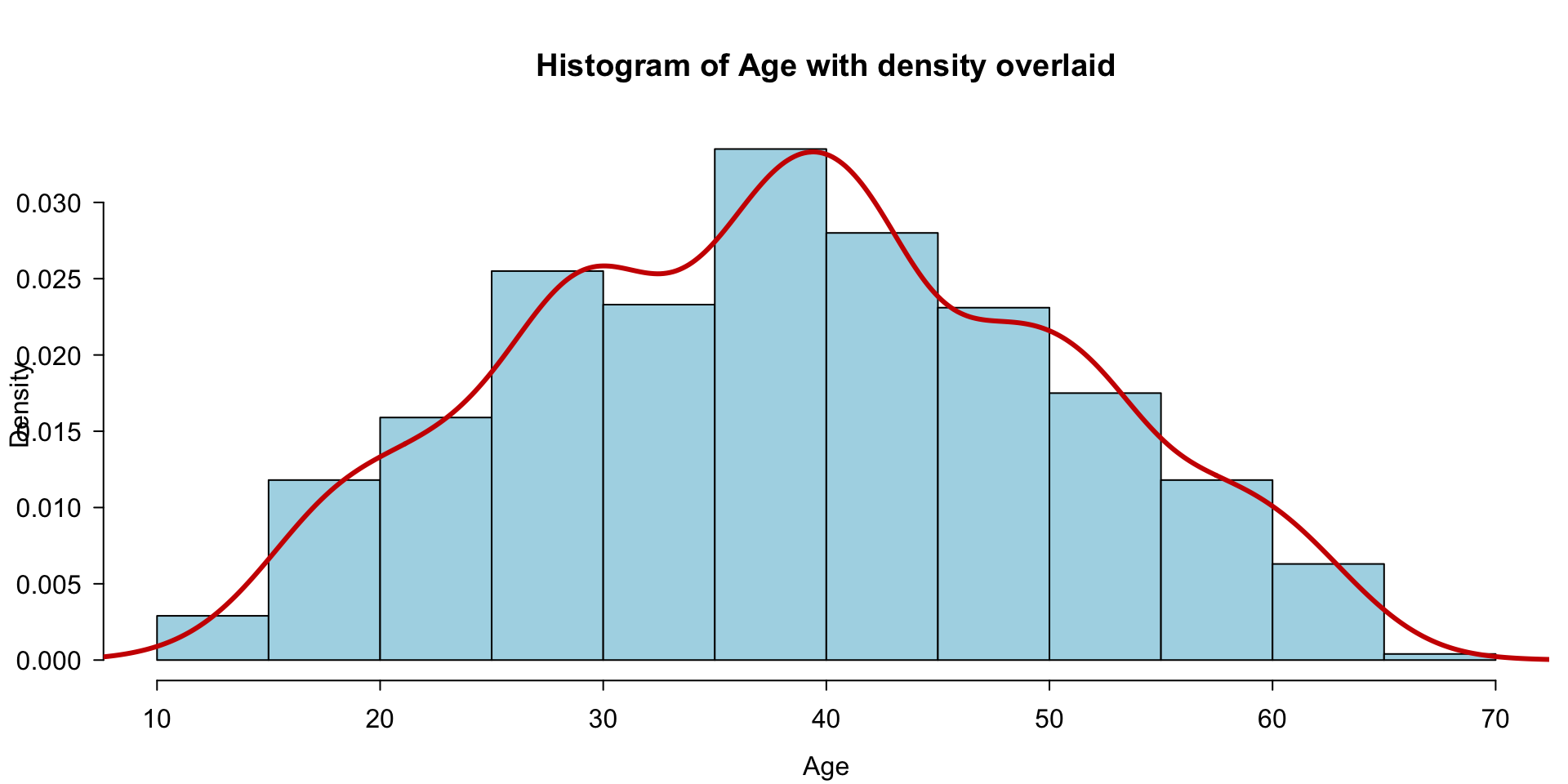
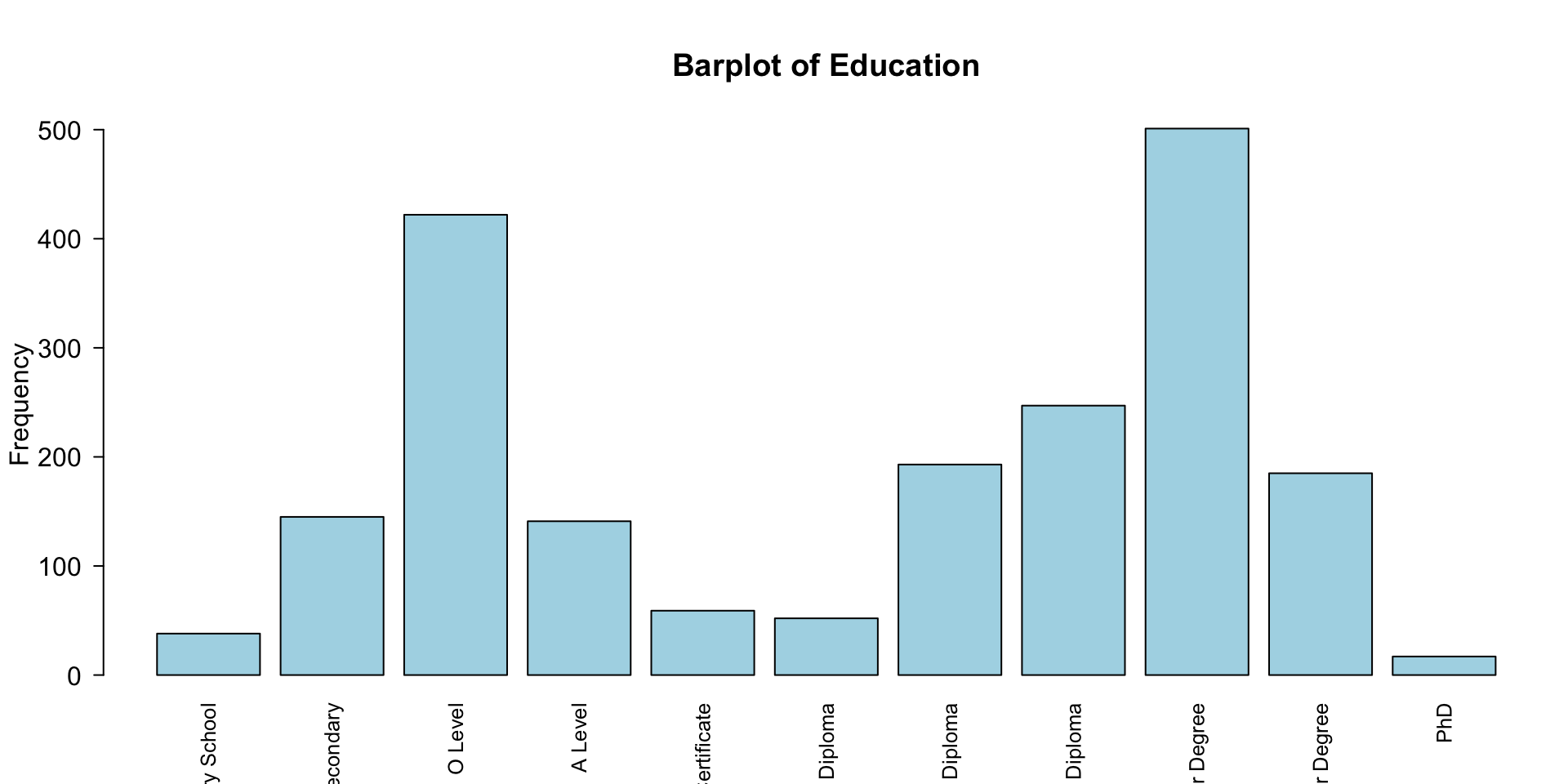
A statistical graphic is a…

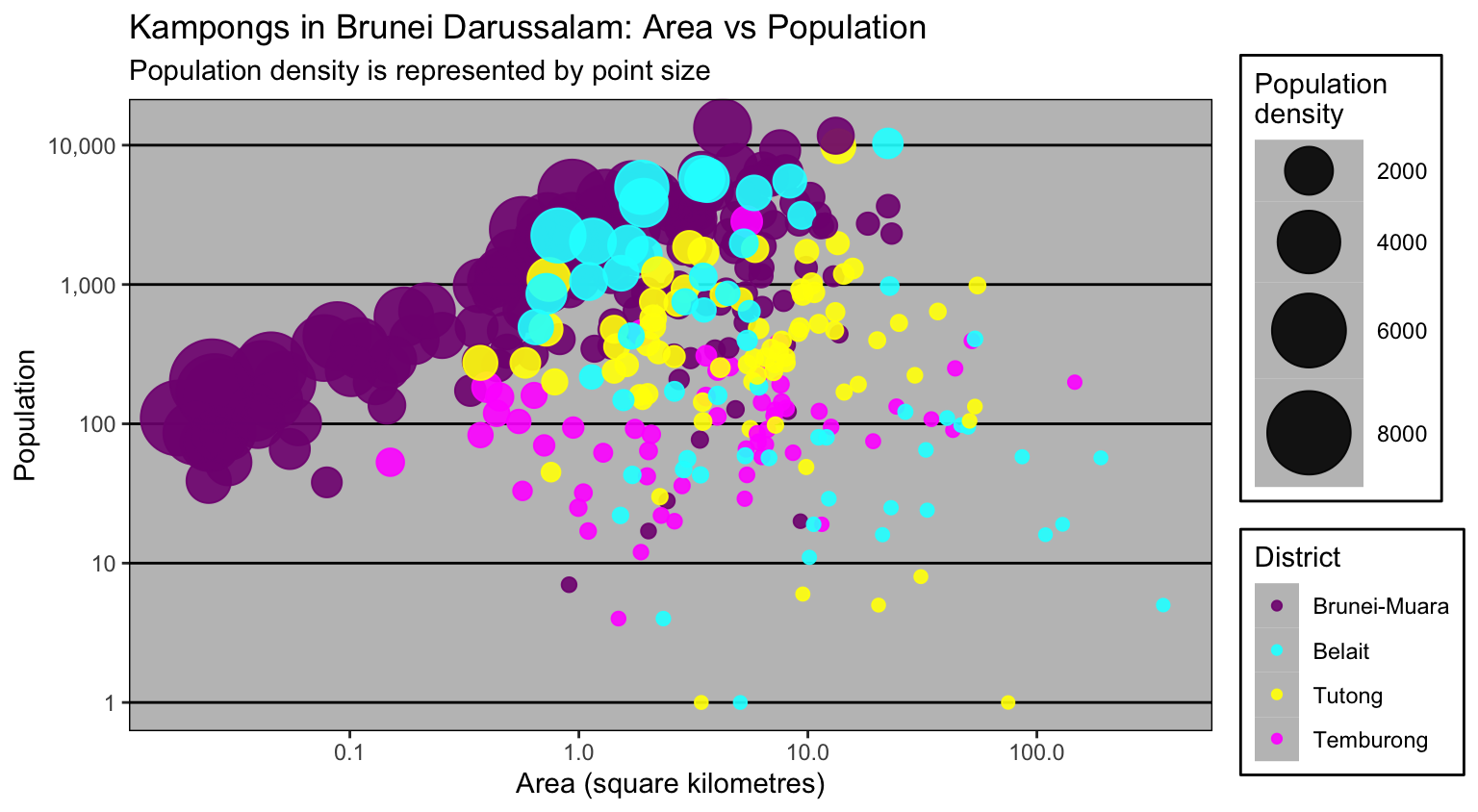
Any \((x,y)\) coordinate data, e.g. locations of
A collection of points connected by lines, e.g.
A closed two-dimensional area formed by connecting a finite number of line segments, e.g.
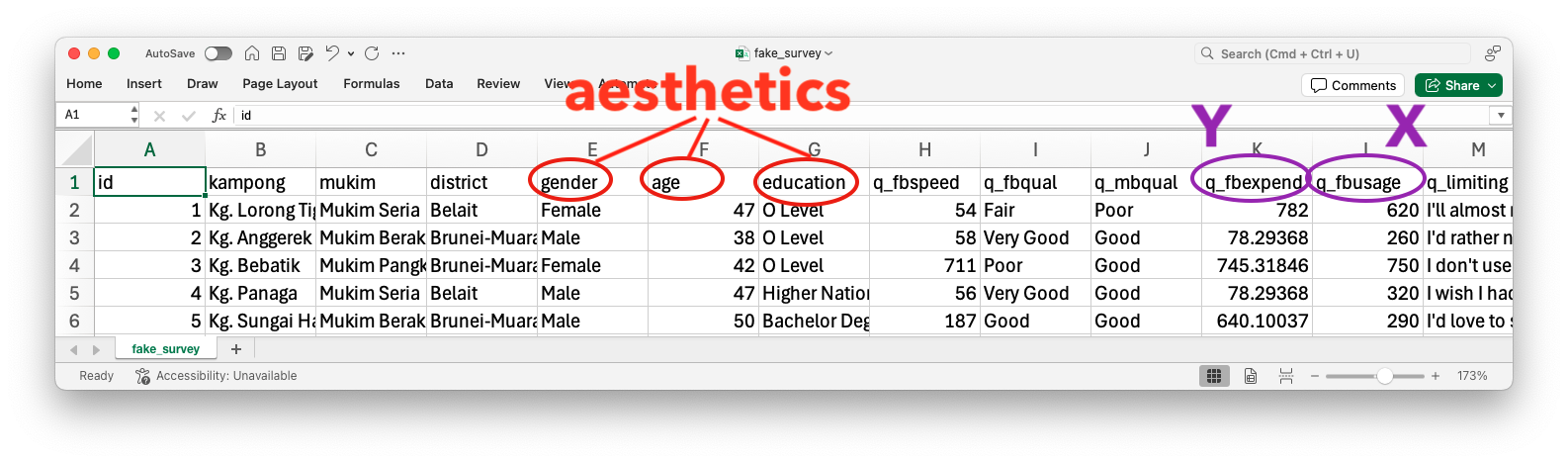
# (Comment section) Describe the top reason that limits your internet access.
head(dat$q_limiting, 5)[1] "I'll almost never download software that costs hundreds of dollars upfront – it's just not worth breaking the bank every five minutes to keep basic services running fine."
[2] "I'd rather not get internet just to pay an extra $50 for installation that'll likely wear off within a year anyway."
[3] "I don't use Video Calls enough because poor calls keep dropping mid-conversation."
[4] "I wish I had reliable internet at home, but it's so easy for me to just use my neighbor's place when I need it."
[5] "I'd love to stream more videos and games if it weren't for how expensive it costs me every month right now." 


Quarto is an open-source scientific and technical publishing system. It enables you to create dynamic documents, reports, presentations, and websites using R code and Markdown language.
DEMO See report.qmd file