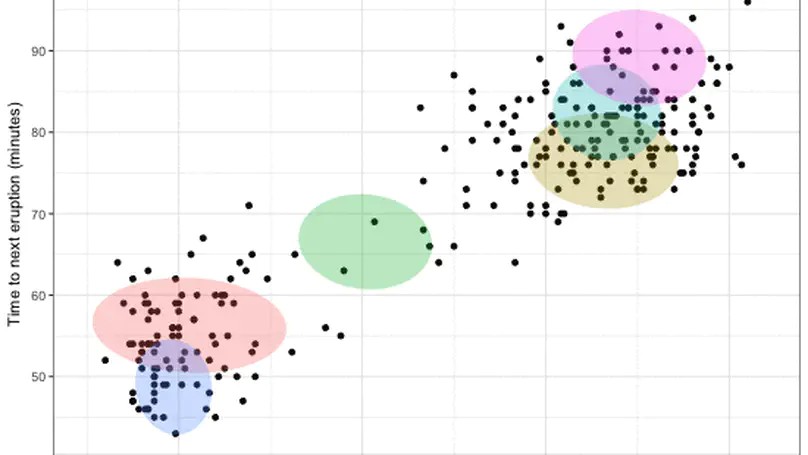
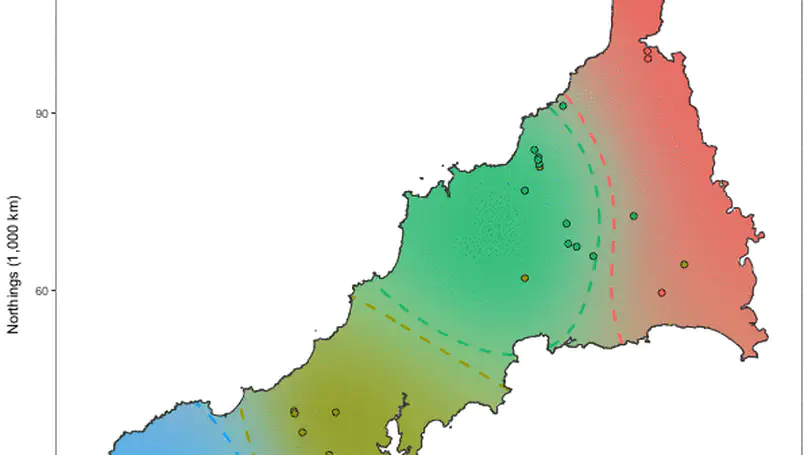
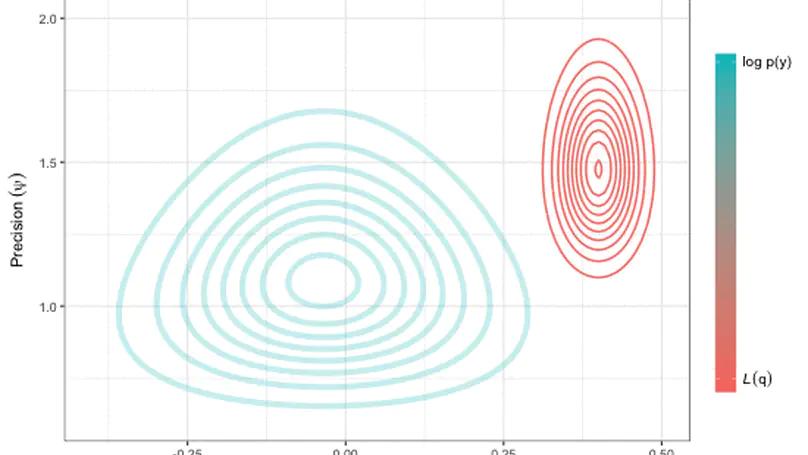
Recent & Upcoming Talks
2025

2024


2022
2021
2020

Soldiers are required to perform tasks that call upon a complex combination of their physical and cognitive capabilities. For example, soldiers are expected to communicate effectively with each other, operate specialised equipment, and maintain overall situational awareness–often while carrying a heavy load. From a planning and doctrine perspective, it is important for commanders to understand the relationship between load carriage and soldiers’ performance. Such information could help provide recommendations in advising future policies on training, operational safety, and future soldier systems requirements. To this end, the Royal Brunei Armed Forces (RBAF) conducted controlled experiments and collected numerous measurements intended to capture key soldier performance parameters. The structure of the data set provided several interesting challenges, namely 1) how do we define “performance”?; 2) how do we appropriately take into account the longitudinal nature of the data (repeated measurements)?; and 3) how do we handle non-ignorable dropouts? We propose a structural equation model to quantify a latent variable representing soldiers’ abilities, while taking into consideration the non-random nature of the dropouts and time-varying effects. The main output of the study is to quantify the relationship between load carried versus performance. Additionally, modelling the dropouts allow us to also determine “expected time to exhaustion” for a given load carried by a soldier.