Weighted pairwise likelihood and limited information goodness-of-fit tests for binary factor models
Adolphe Quetelet Seminar Series, Ghent University
Haziq Jamil 
Assistant Professor in Statistics, Universiti Brunei Darussalam
Visiting Fellow, London School of Economics and Political Science
April 15, 2024

London School of Economics and Political Science

London School of Economics and Political Science
H Jamil, I Moustaki, C Skinner. 2023+. Pairwise likelihood estimation and limited information goodness-of-fit test statistics for binary factor analysis models under complex survey sampling. Manuscript under revision.
Introduction

Behavioural checklist

Achievement test

Intergenerational support
Parametric models
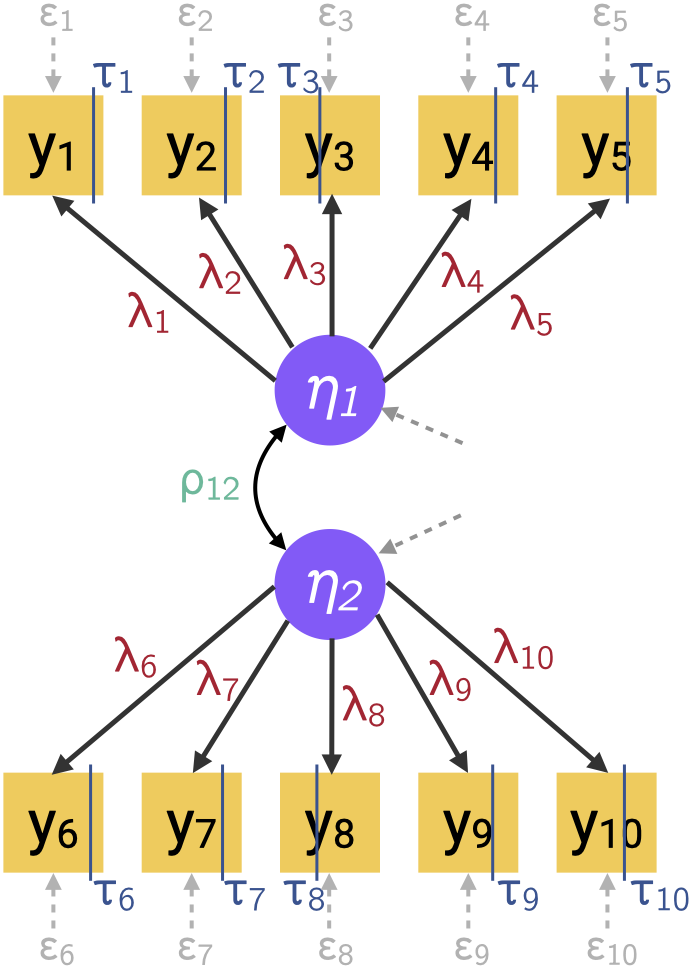
- E.g. binary factor model with underlying variable approach (s.t. constraints) \[ \begin{gathered} y_i = \begin{cases} 1 & y_i^* > \tau_i \\ 0 & y_i^* \leq \tau_i \end{cases} \\ {\mathbf y}^* = {\boldsymbol\Lambda}{\boldsymbol\eta}+ {\boldsymbol\epsilon}\\ {\boldsymbol\eta}\sim {\mathop{\mathrm{N}}}_q({\mathbf 0}, {\boldsymbol\Psi}), \hspace{3pt} {\boldsymbol\epsilon}\sim {\mathop{\mathrm{N}}}_p({\mathbf 0}, {\boldsymbol\Theta}_{\epsilon}) \end{gathered} \tag{4}\]
- The log-likelihood for \({\boldsymbol\theta}^\top = (\)\({\boldsymbol\lambda}\)\(,\,\)\({\boldsymbol\rho}\)\(,\,\)\({\boldsymbol\tau}\)\()\in\mathbb{R}^m\) is \[ \log L({\boldsymbol\theta}\mid {\mathcal Y}) = \sum_{r=1}^R \hat n_r \log \pi_r({\boldsymbol\theta}) \tag{5}\] where \(\pi_r({\boldsymbol\theta}) = \int \phi_p({\mathbf y}^* \mid {\mathbf 0}, {\boldsymbol\Lambda}{\boldsymbol\Psi}{\boldsymbol\Lambda}^\top + {\boldsymbol\Theta}_\epsilon) \mathop{\mathrm{d}}\hspace{0.5pt}\!{\mathbf y}^*\).
- FIML may be difficult (high-dimensional integral; perfect separation).
An analogy





One may enjoy the approximate picture despite
not being able to see every blade of grass.
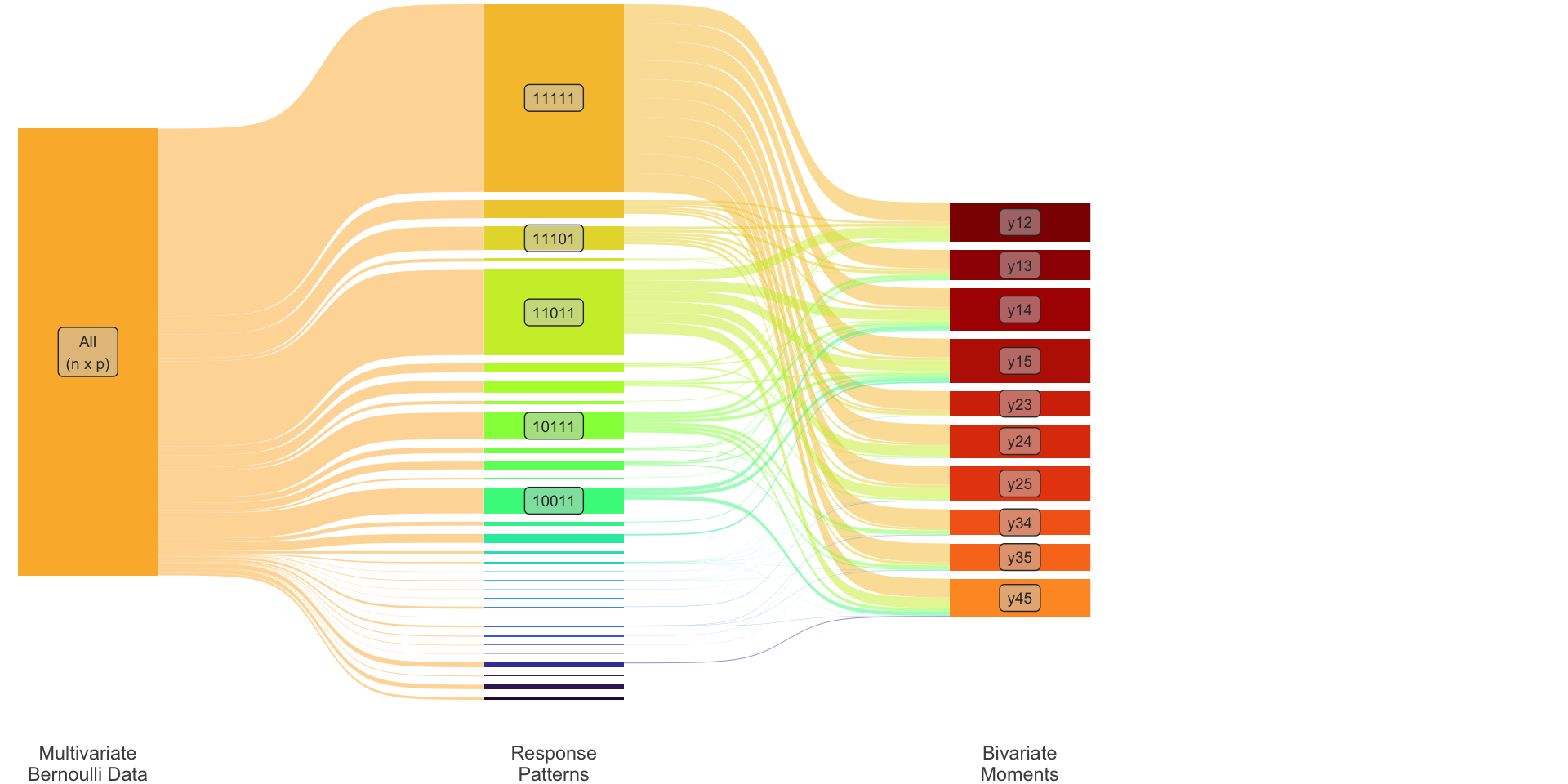
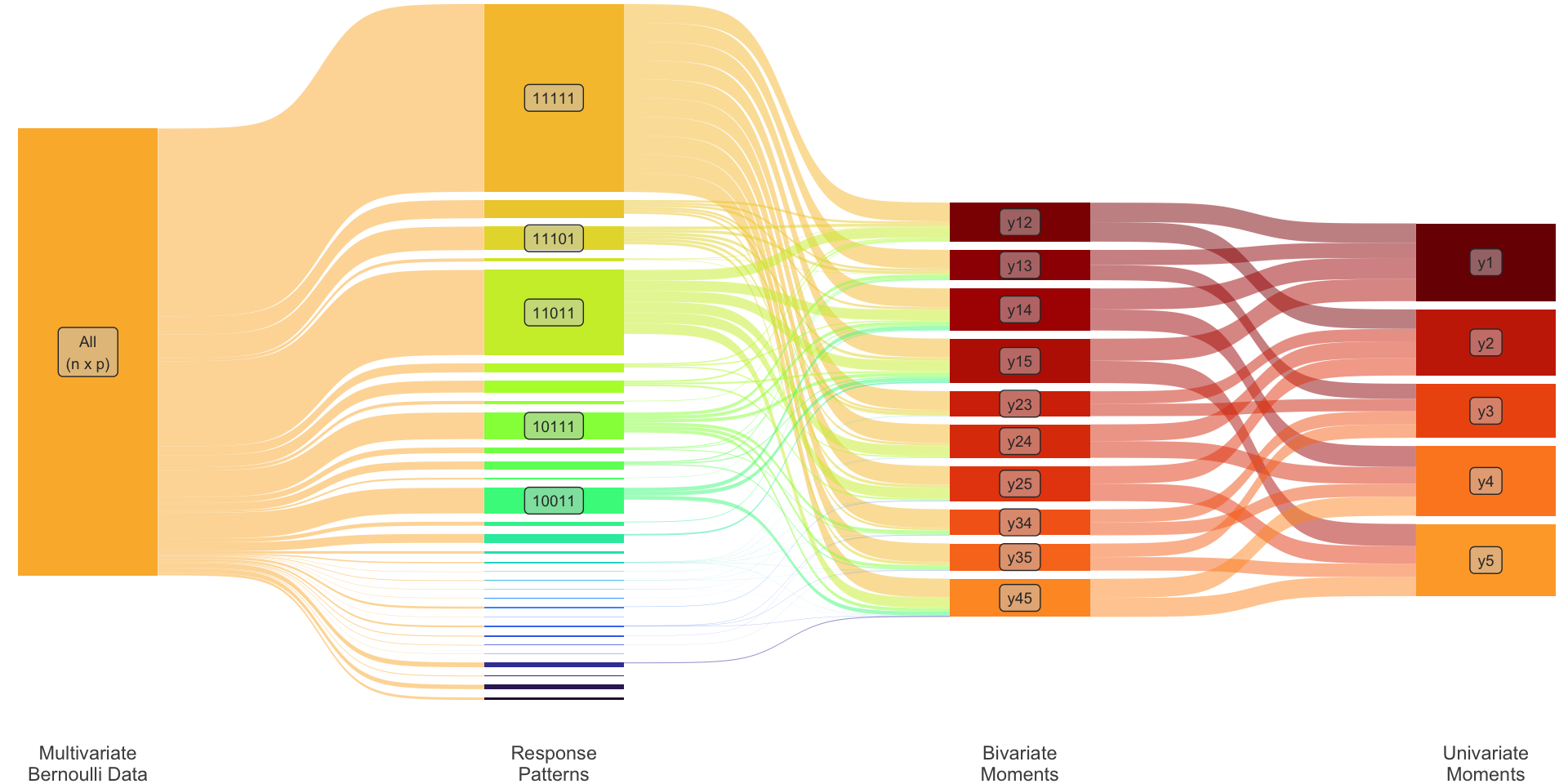
Limited information goodness-of-fit (LIGOF)
Consider instead the fit of the lower order marginals.
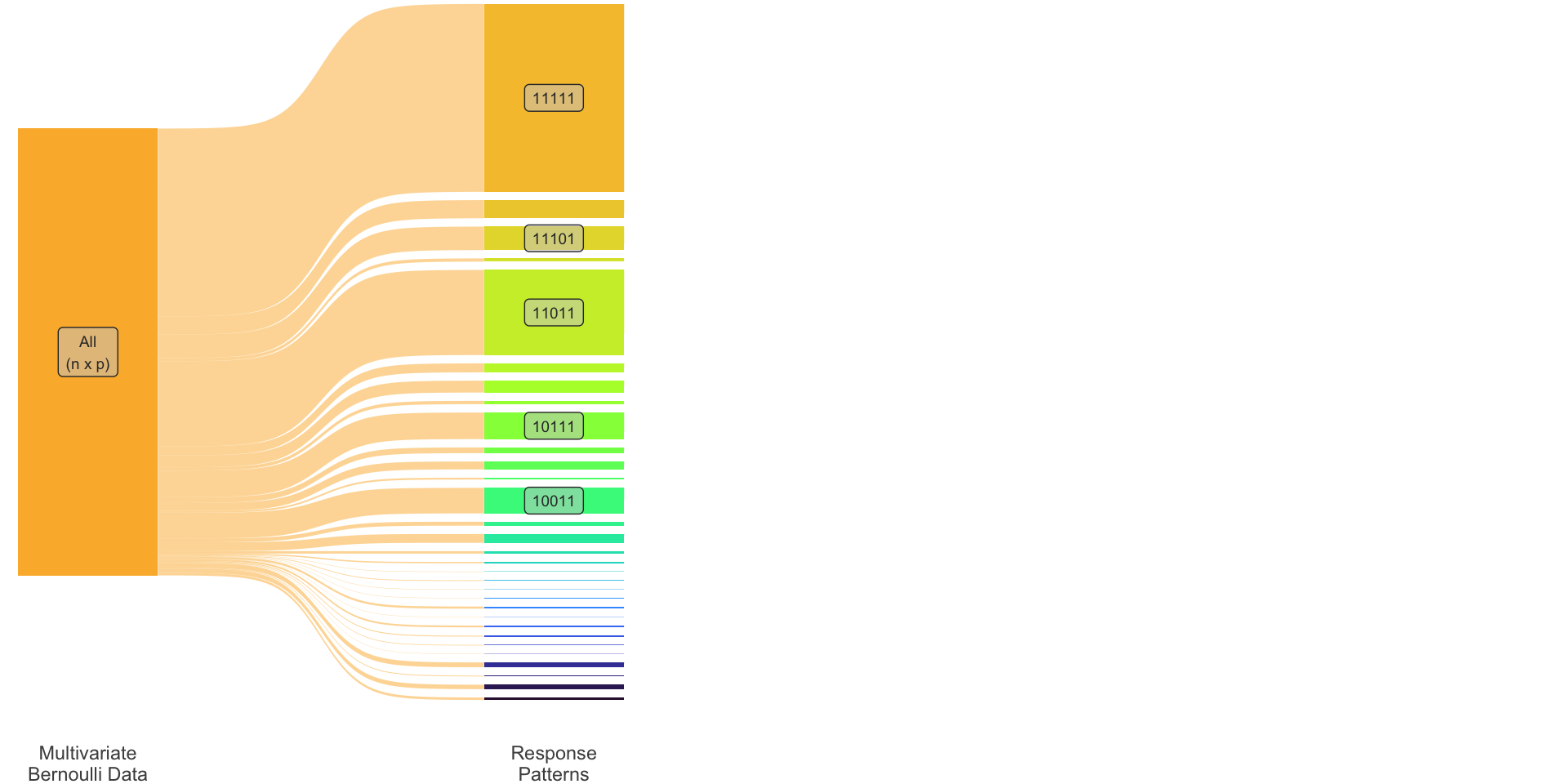
Univariate: \(\ \dot\pi_i := \operatorname{P}(y_i = 1)\)
Bivariate: \(\ \dot\pi_{ij} := \operatorname{P}(y_i = 1, y_j=1)\)
Collectively \[ {\boldsymbol\pi}_2 = \begin{pmatrix} \dot{\boldsymbol\pi}_1 \\ \dot{\boldsymbol\pi}_2 \\ \end{pmatrix} = \begin{pmatrix} (\dot\pi_1, \dots, \dot\pi_p)^\top \\ \big(\dot\pi_{ij}\big)_{i<j} \\ \end{pmatrix} \] This is of dimensions \[ S=p + p(p-1)/2 \ll R. \]
Factor models
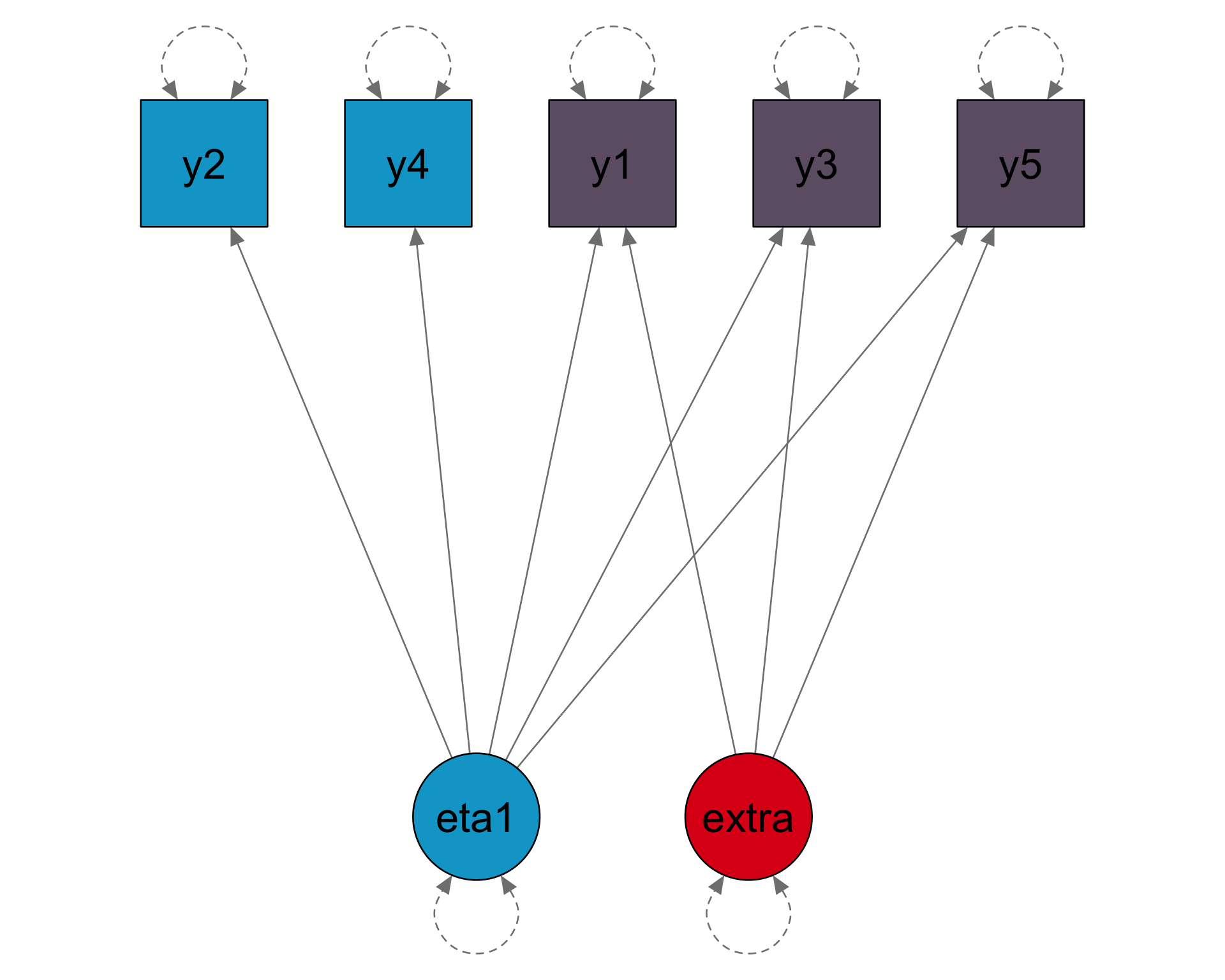
Loadings
5 x 1 sparse Matrix of class "dgCMatrix"
[1,] 0.80
[2,] 0.70
[3,] 0.47
[4,] 0.38
[5,] 0.34
Thresholds
[1] -1.43 -0.55 -0.13 -0.72
[5] -1.13
Factor correlations
[1] 1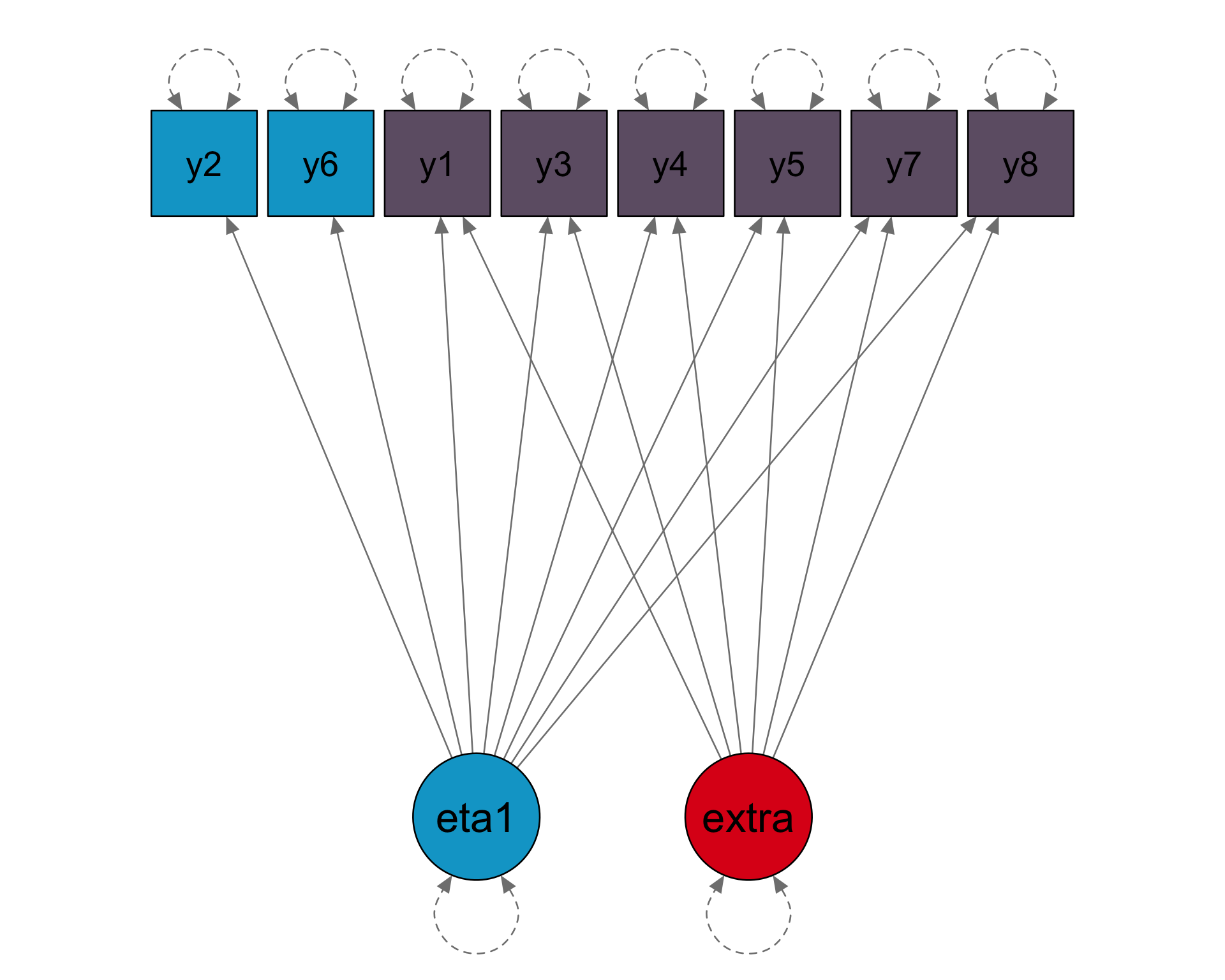
Loadings
8 x 1 sparse Matrix of class "dgCMatrix"
[1,] 0.80
[2,] 0.70
[3,] 0.47
[4,] 0.38
[5,] 0.34
[6,] 0.80
[7,] 0.70
[8,] 0.47
Thresholds
[1] -1.43 -0.55 -0.13 -0.72
[5] -1.13 -1.43 -0.55 -0.13
Factor correlations
[1] 1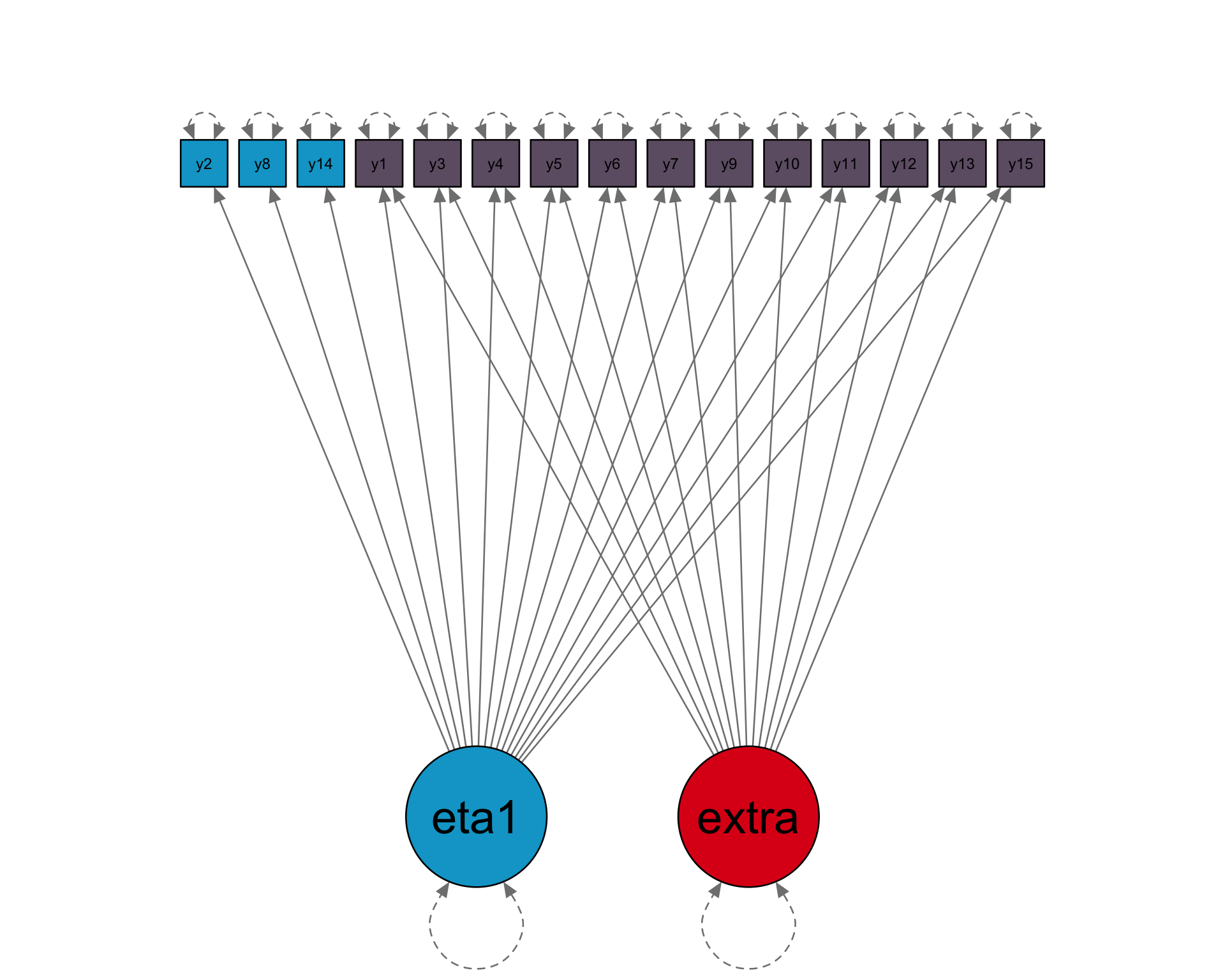
Loadings
15 x 1 sparse Matrix of class "dgCMatrix"
[1,] 0.80
[2,] 0.70
[3,] 0.47
[4,] 0.38
[5,] 0.34
[6,] 0.80
[7,] 0.70
[8,] 0.47
[9,] 0.38
[10,] 0.34
[11,] 0.80
[12,] 0.70
[13,] 0.47
[14,] 0.38
[15,] 0.34
Thresholds
[1] -1.43 -0.55 -0.13 -0.72
[5] -1.13 -1.43 -0.55 -0.13
[9] -0.72 -1.13 -1.43 -0.55
[13] -0.13 -0.72 -1.13
Factor correlations
[1] 1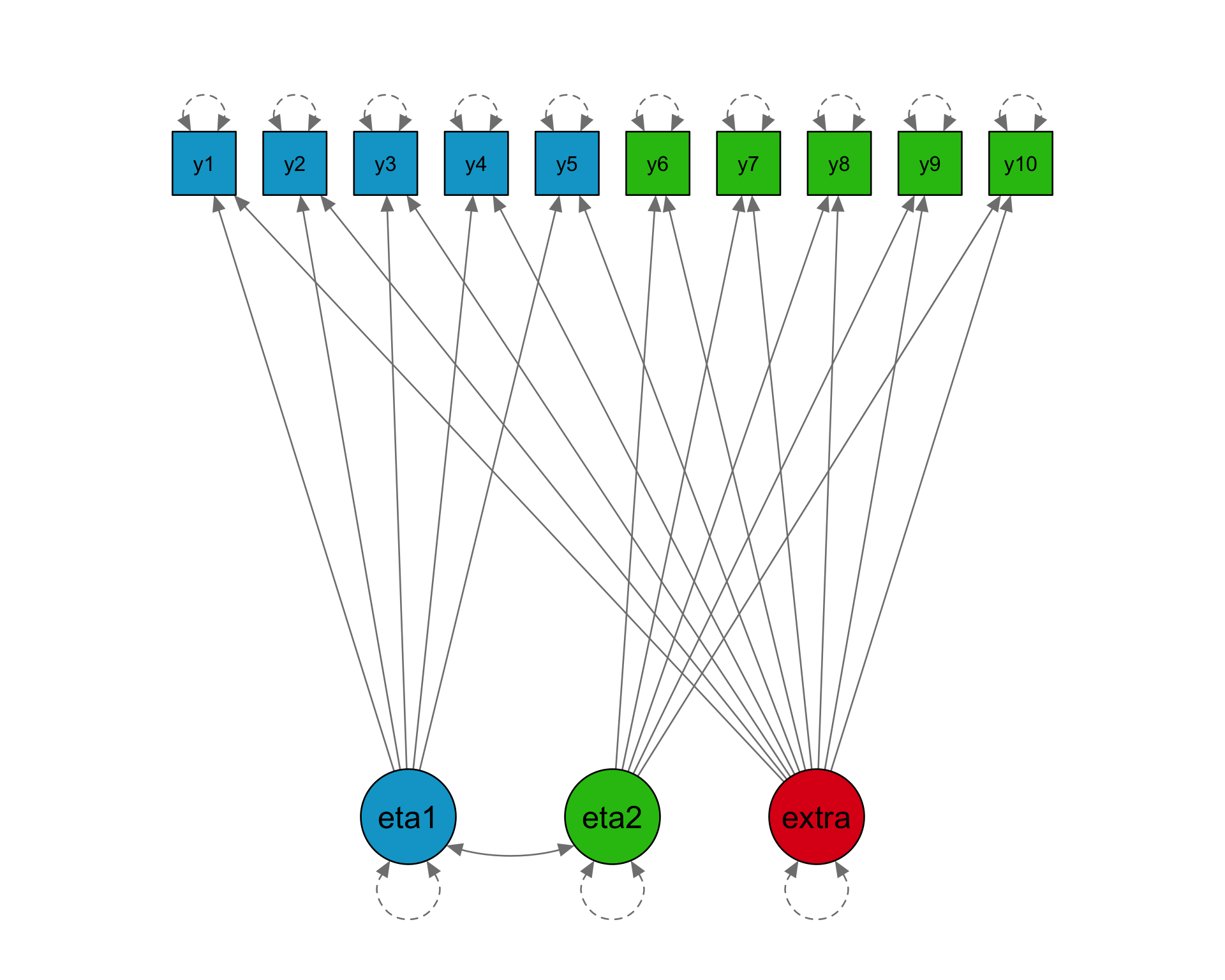
Loadings
10 x 2 sparse Matrix of class "dgCMatrix"
[1,] 0.80 .
[2,] 0.70 .
[3,] 0.47 .
[4,] 0.38 .
[5,] 0.34 .
[6,] . 0.80
[7,] . 0.70
[8,] . 0.47
[9,] . 0.38
[10,] . 0.34
Thresholds
[1] -1.43 -0.55 -0.13 -0.72
[5] -1.13 -1.43 -0.55 -0.13
[9] -0.72 -1.13
Factor correlations
[,1] [,2]
[1,] 1.0 0.3
[2,] 0.3 1.0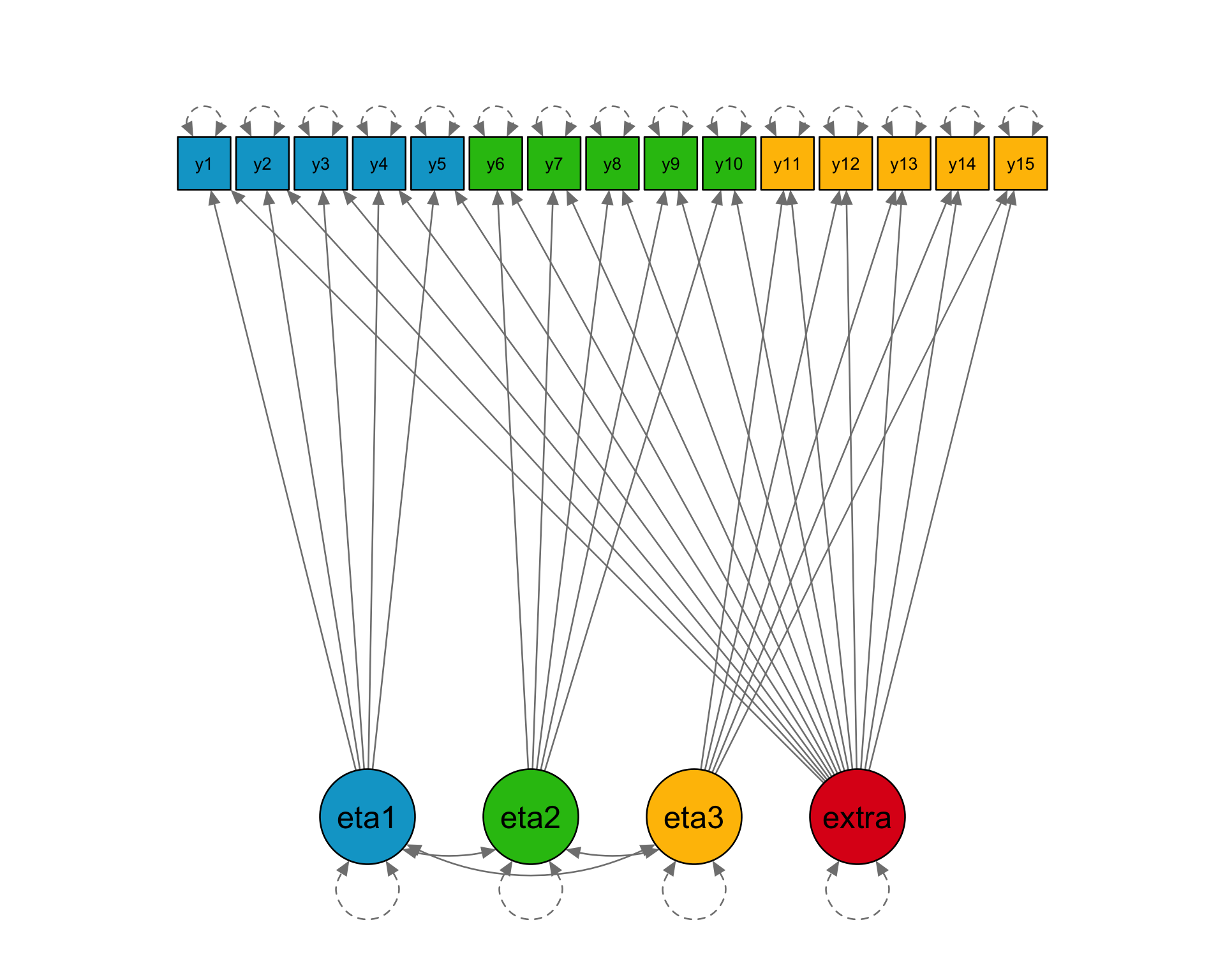
Loadings
15 x 3 sparse Matrix of class "dgCMatrix"
[1,] 0.80 . .
[2,] 0.70 . .
[3,] 0.47 . .
[4,] 0.38 . .
[5,] 0.34 . .
[6,] . 0.80 .
[7,] . 0.70 .
[8,] . 0.47 .
[9,] . 0.38 .
[10,] . 0.34 .
[11,] . . 0.80
[12,] . . 0.70
[13,] . . 0.47
[14,] . . 0.38
[15,] . . 0.34
Thresholds
[1] -1.43 -0.55 -0.13 -0.72
[5] -1.13 -1.43 -0.55 -0.13
[9] -0.72 -1.13 -1.43 -0.55
[13] -0.13 -0.72 -1.13
Factor correlations
[,1] [,2] [,3]
[1,] 1.0 0.2 0.3
[2,] 0.2 1.0 0.4
[3,] 0.3 0.4 1.0Educational survey
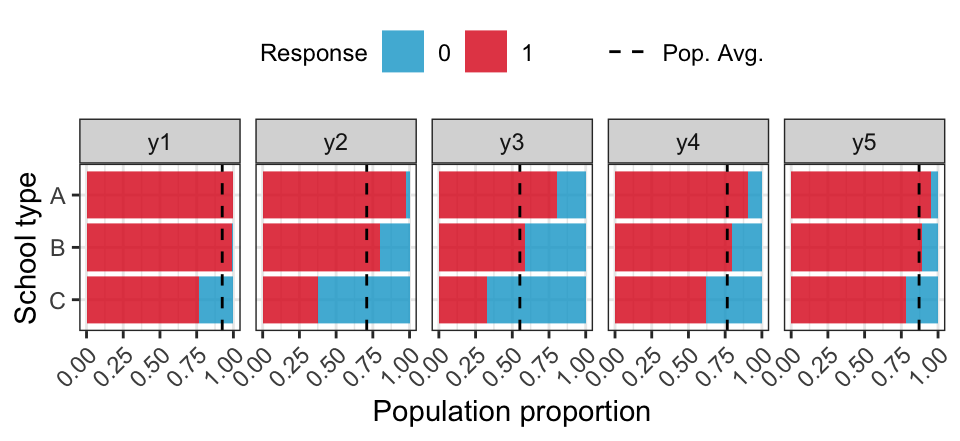
Simulate a population of \(1e6\) students clustered within classrooms and stratified by school type (correlating with abilities).
| Type | \(N\) | Classes | Avg. class size |
|---|---|---|---|
| A | 400 | 33.0 | 15.2 |
| B | 1000 | 19.6 | 25.6 |
| C | 600 | 24.9 | 20.4 |
ICC for test items range between 0.05 and 0.60.
- Cluster sample: Sample \(n_C\) schools using PPS, then sample 1 classroom via SRS, then select all students in classroom.
- Stratified cluster sample: For each stratum, sample \(n_S\) schools using SRS, then sample 1 classroom via SRS, then select all students in classroom.
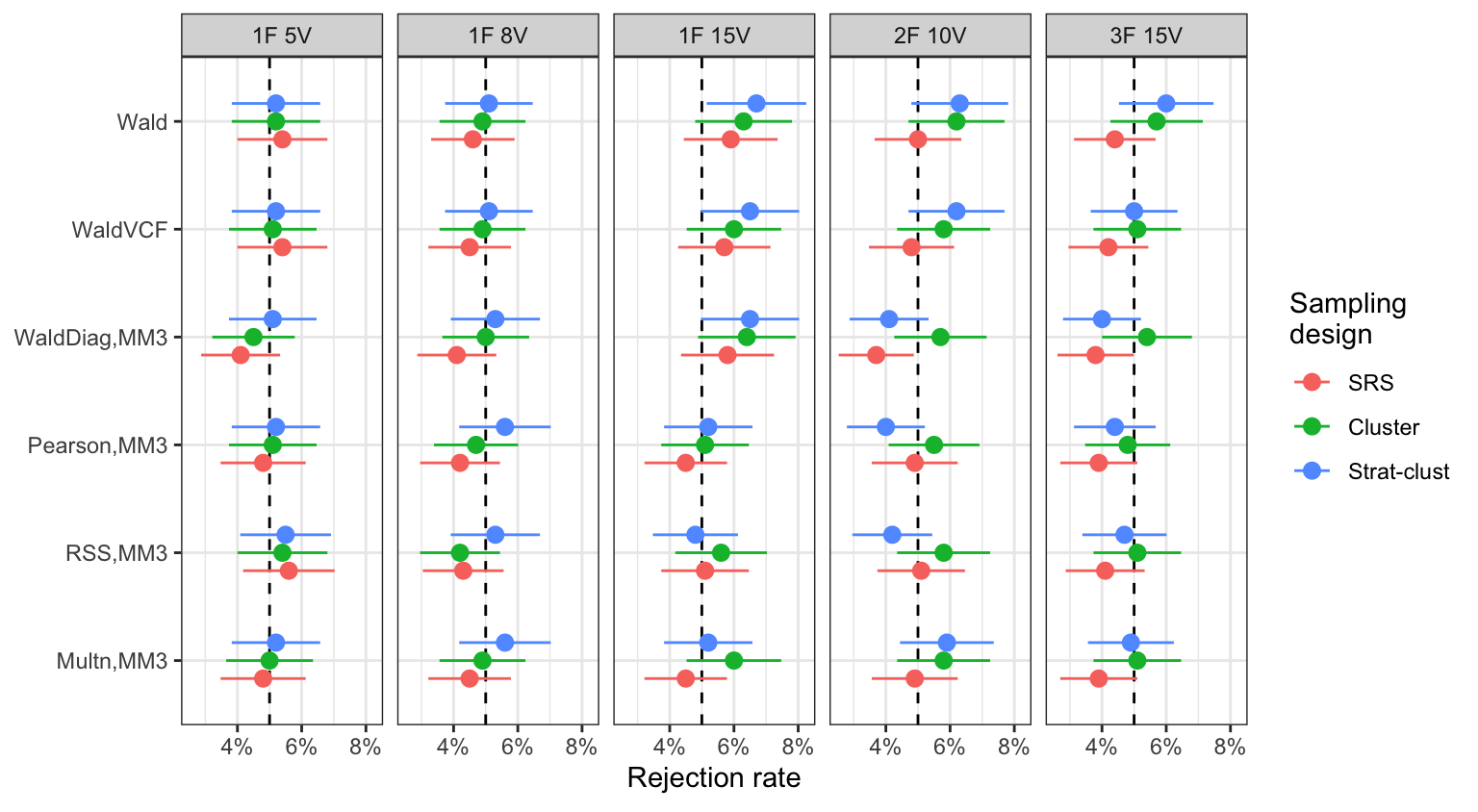
Educational survey (results)
Type I error rates (5% level, \(n=5000\))
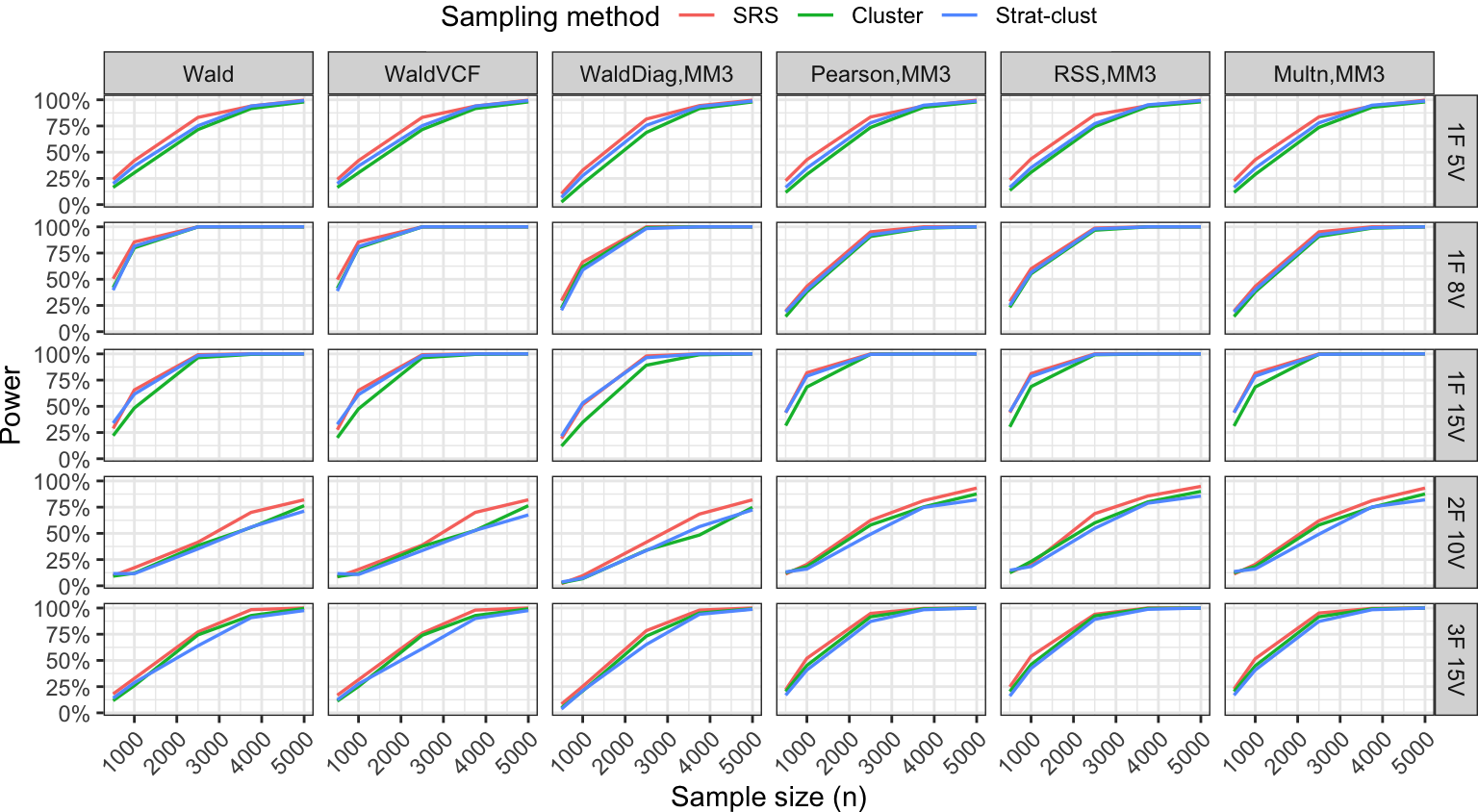
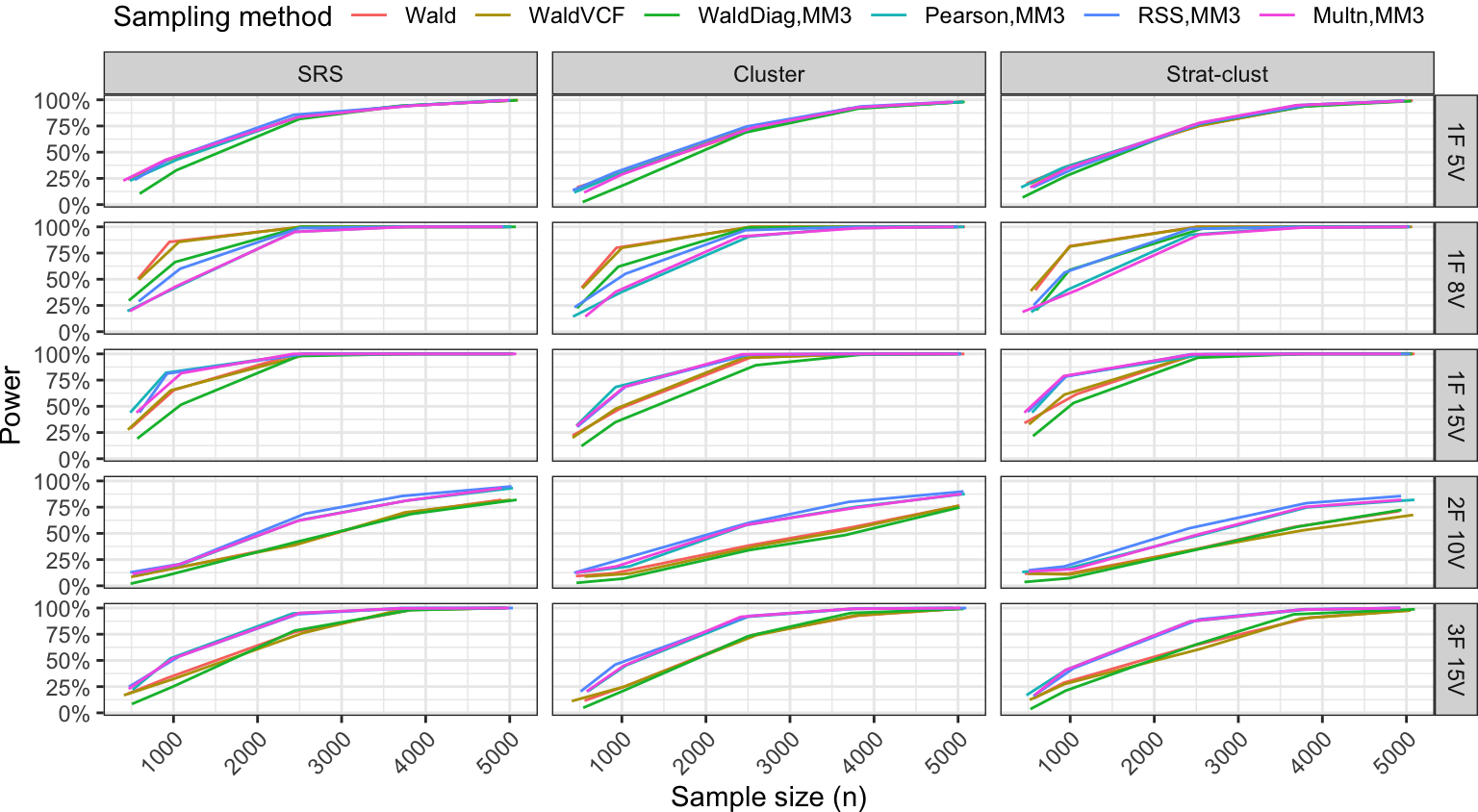
Educational survey (results)
Power analysis
References
![]()
Agresti, Alan. 2012. Categorical Data Analysis. Vol. 792. John Wiley & Sons.
Asparouhov, Tihomir. 2005. “Sampling Weights in Latent Variable Modeling.” Structural Equation Modeling 12 (3): 411–34.
Bartholomew, David J, and Shing On Leung. 2002. “A Goodness of Fit Test for Sparse 2p Contingency Tables.” British Journal of Mathematical and Statistical Psychology 55 (1): 1–15.
Besag, Julian. 1974. “Spatial Interaction and the Statistical Analysis of Lattice Systems.” Journal of the Royal Statistical Society: Series B (Methodological) 36 (2): 192–225. https://doi.org/10.1111/j.2517-6161.1974.tb00999.x.
Cai, Li., Albert. Maydeu‐Olivares, Donna L. Coffman, and David. Thissen. 2006. “Limited‐information Goodness‐of‐fit Testing of Item Response Theory Models for Sparse 2 P Tables.” British Journal of Mathematical and Statistical Psychology 59 (1): 173–94. https://doi.org/10.1348/000711005X66419.
Chandler, Richard E., and Steven Bate. 2007. “Inference for Clustered Data Using the Independence Loglikelihood.” Biometrika 94 (1): 167–83. https://www.jstor.org/stable/20441361.
Cox, D. R., and N. Reid. 2004. “A Note on Pseudolikelihood Constructed from Marginal Densities.” Biometrika 91 (3): 729–37. https://www.jstor.org/stable/20441134.
Fuller, Wayne A. 2009. Introduction to Statistical Time Series. John Wiley & Sons.
Katsikatsou, Myrsini, Irini Moustaki, Fan Yang-Wallentin, and Karl G Jöreskog. 2012. “Pairwise Likelihood Estimation for Factor Analysis Models with Ordinal Data.” Computational Statistics & Data Analysis 56 (12): 4243–58.
Liang, Kung-Yee. 1987. “Extended Mantel-Haenszel Estimating Procedure for Multivariate Logistic Regression Models.” Biometrics 43 (2): 289–99. https://doi.org/10.2307/2531813.
Lindsay, Bruce G. 1988. “Composite Likelihood Methods.” In Contemporary Mathematics, edited by N. U. Prabhu, 80:221–39. Providence, Rhode Island: American Mathematical Society. https://doi.org/10.1090/conm/080/999014.
Lumley, Thomas. 2004. “Analysis of Complex Survey Samples.” Journal of Statistical Software 9 (April): 1–19. https://doi.org/10.18637/jss.v009.i08.
Mathai, Arakaparampil M, and Serge B Provost. 1992. Quadratic Forms in Random Variables: Theory and Applications. Dekker.
Maydeu-Olivares, Alberto, and Harry Joe. 2005. “Limited- and Full-Information Estimation and Goodness-of-Fit Testing in \(2^n\) Contingency Tables: A Unified Framework.” Journal of the American Statistical Association 100 (471): 1009–20.
———. 2008. “An Overview of Limited Information Goodness-of-Fit Testing in Multidimensional Contingency Tables.” New Trends in Psychometrics, 253–62.
Molenberghs, Geert, and Geert Verbeke. 2006. Models for Discrete Longitudinal Data. Nachdr. Springer Series in Statistics. New York, NY: Springer.
Muthén, Bengt O., and Albert Satorra. 1995. “Complex Sample Data in Structural Equation Modeling.” Sociological Methodology 25: 267–316. https://doi.org/10.2307/271070.
Reiser, Mark. 1996. “Analysis of Residuals for the Multionmial Item Response Model.” Psychometrika 61: 509–28.
Skinner, C. J. 1989. “Domain Means, Regression and Multivariate Analysis.” In Analysis of Complex Surveys, edited by C. J. Skinner, D. Holt, and T. M. F. Smith, 59–87. Wiley Series in Probability and Mathematical Statistics. Chichester; New York: Wiley.
Varin, Cristiano. 2008. “On Composite Marginal Likelihoods.” AStA Advances in Statistical Analysis 92 (1): 1–28. https://doi.org/10.1007/s10182-008-0060-7.
Varin, Cristiano, Nancy Reid, and David Firth. 2011. “An Overview of Composite Likelihood Methods.” Statistica Sinica, 5–42.
Wedderburn, R. W. M. 1974. “Quasi-Likelihood Functions, Generalized Linear Models, and the Gauss-Newton Method.” Biometrika 61 (3): 439–47. https://doi.org/10.2307/2334725.
Zhao, Y, and H. Joe. 2005. “Composite Likelihood Estimation in Multivariate Data Analysis.” Tha Canadian Journal of Statistics 33 (3): 335–56.