Spatio-temporal modelling of property prices in Brunei Darussalam
LSE Social Statistics Seminar
Haziq Jamil 
Assistant Professor of Statistics
Universiti Brunei Darussalam
October 26, 2023
The team
Statistical modelling of spatio-temporal data in Brunei Darussalam

Types of spatial data
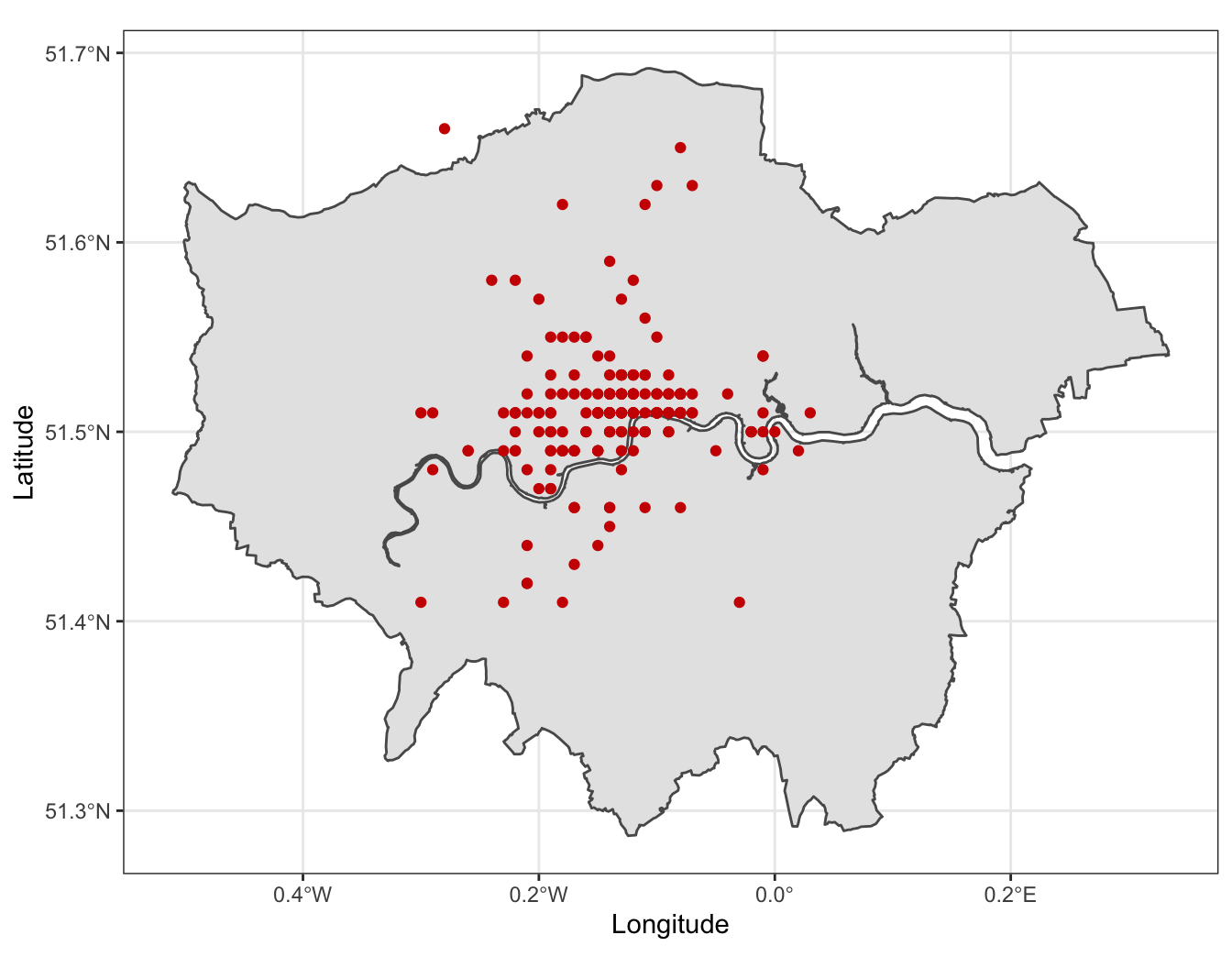
Location of Starbucks® around London.
Data source: Kaggle
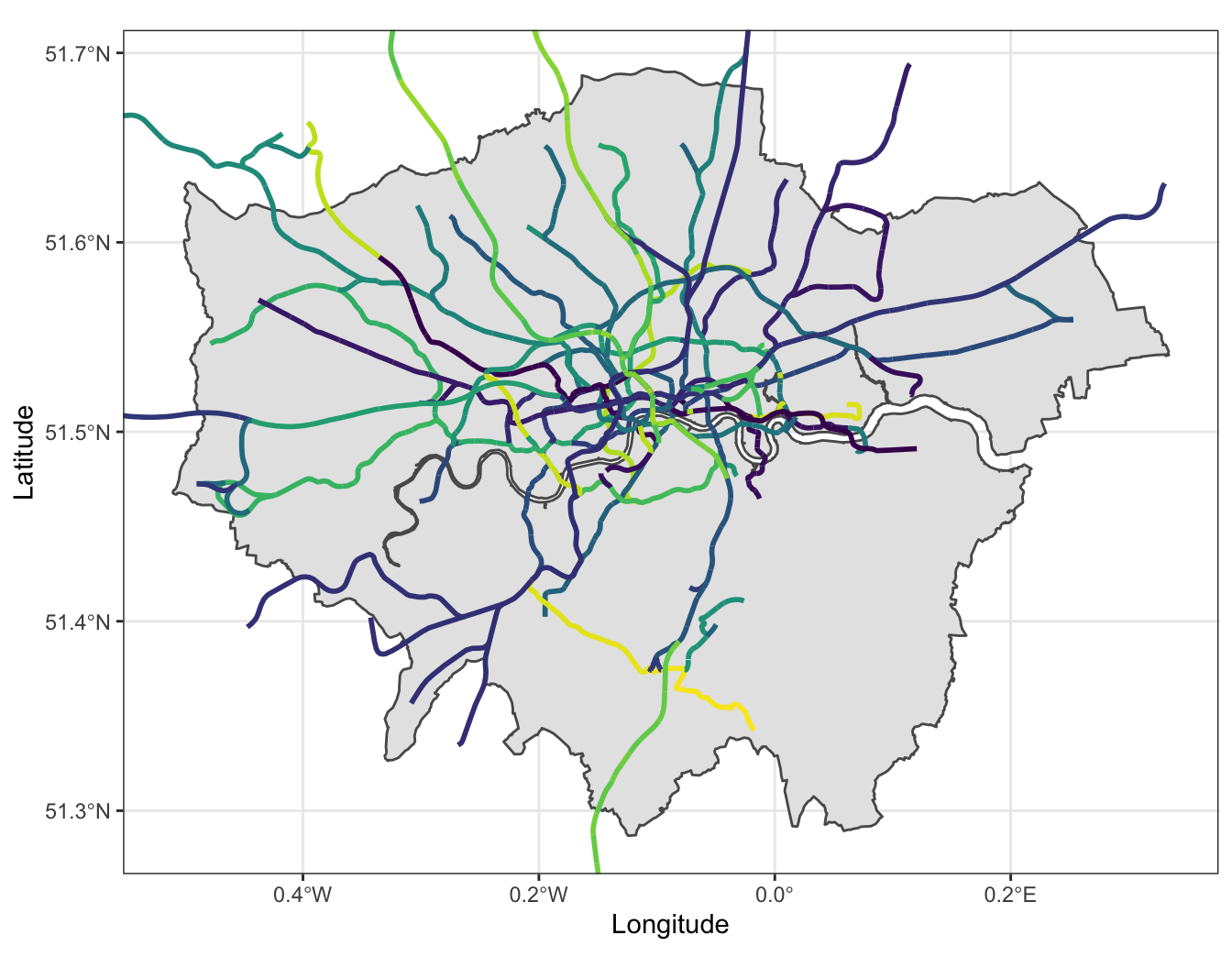
Transport for London (TFL) Tube, Overground, Elizabeth line, DLR & Tram lines (including Crossrail alignment)
Data source: github/oobrien
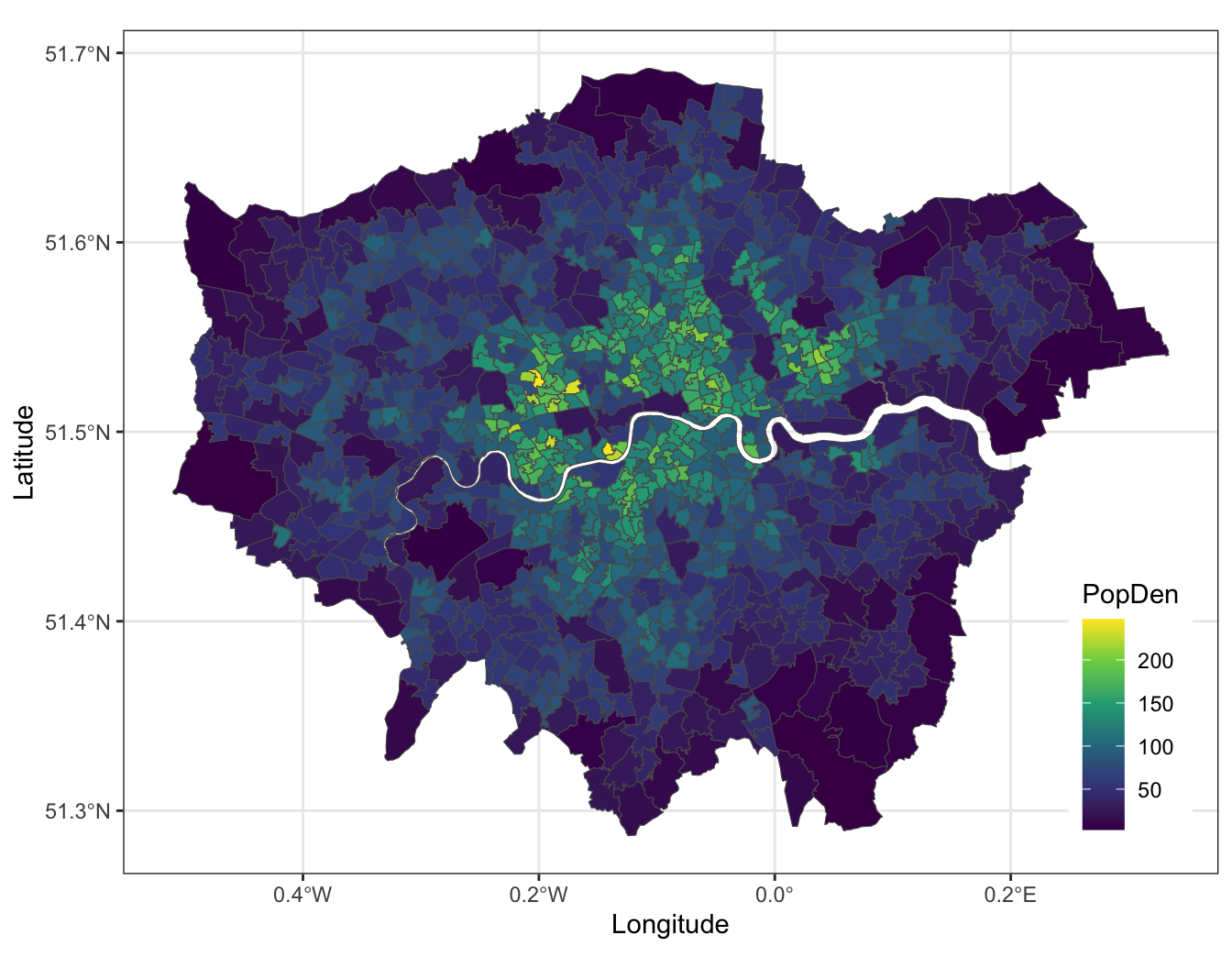
London Middle Super Output Area (MSOA) population density (2011).
Data source: London Datastore
- Geospatial points vs point processes
- Point processes: Locations are random variables (e.g. earthquakes, crime, diseases, etc.)
- Geospatial points: Locations are fixed
- Raster/Grid data
- Pixelated (or gridded) data where each pixel is associated with a specific geographical location
- E.g. satellite imagery, digital elevation models, etc.
- Network data.
- E.g. road networks, social networks, etc.
Spatial data in R
- Simple features refers to a formal standard (ISO 19125-1:2004) that describes how objects in the real world can be represented in computers, with emphasis on the spatial geometry of these objects.
- The
{sf}package (Pebesma and Bivand 2023) provides support for handling spatial data in R.

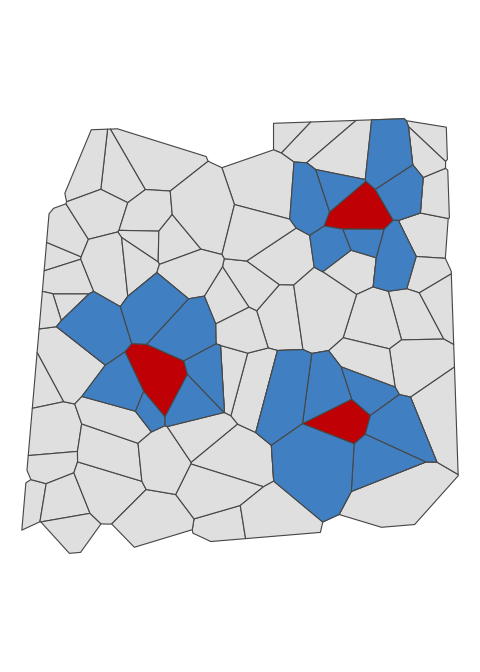
Types of spatial patterns
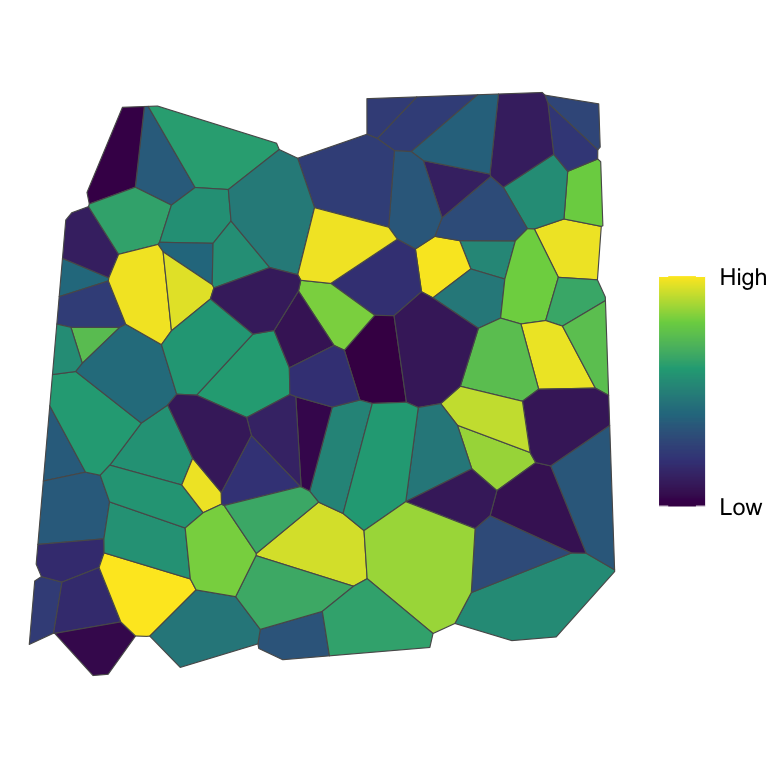
Values are randomly distributed in space, independently of each other (and particularly its neighbours)
Lack of a spatial pattern.
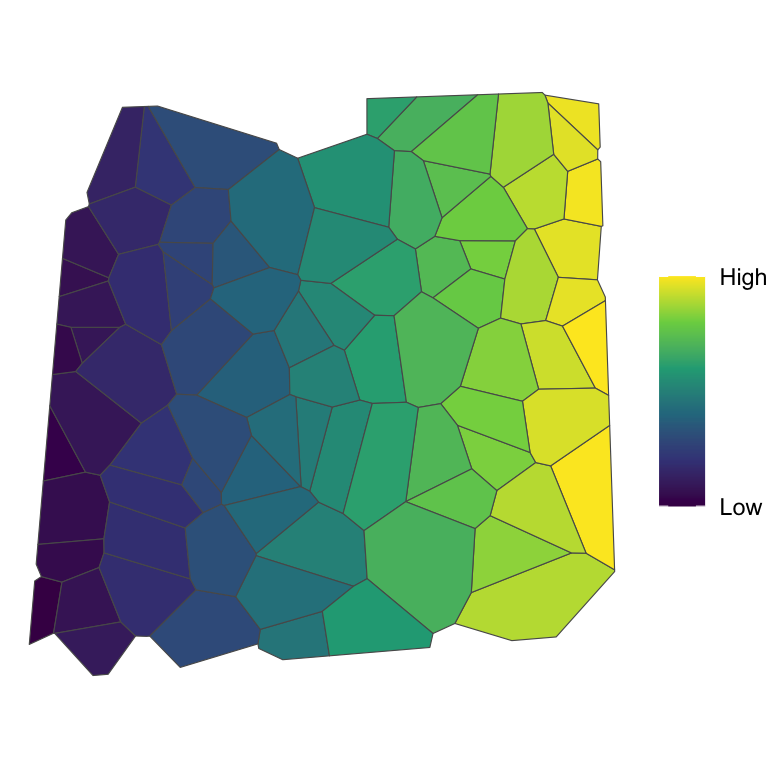
Values are non-randomly distributed in space.
Large values are “attracting” other large values, and vice versa.
A clustering effect is present.
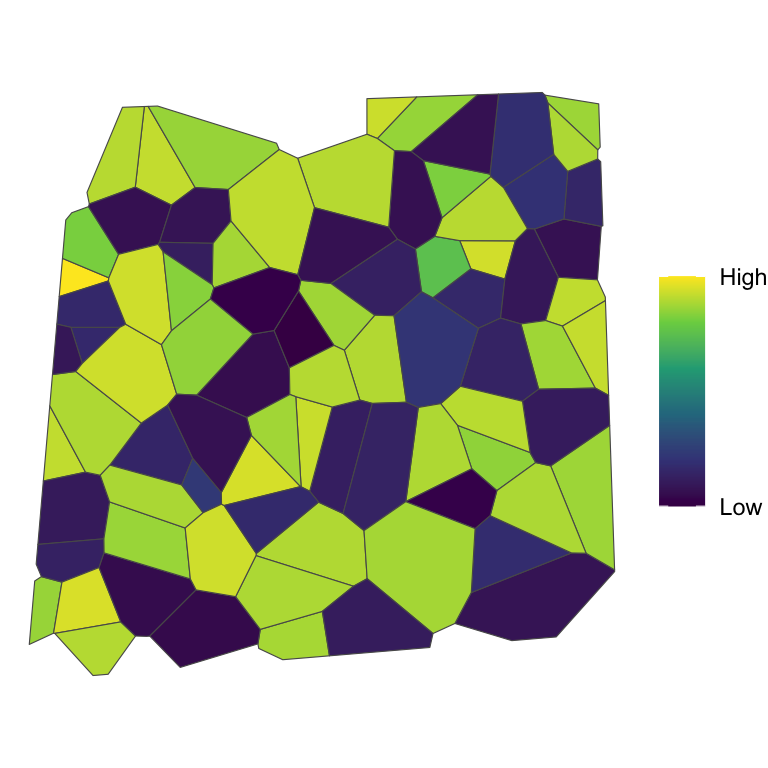
Values are non-randomly distributed in space.
Large values are “repelling” other large values, and vice versa.
A dispersion effect is present.
Neighbour definitions
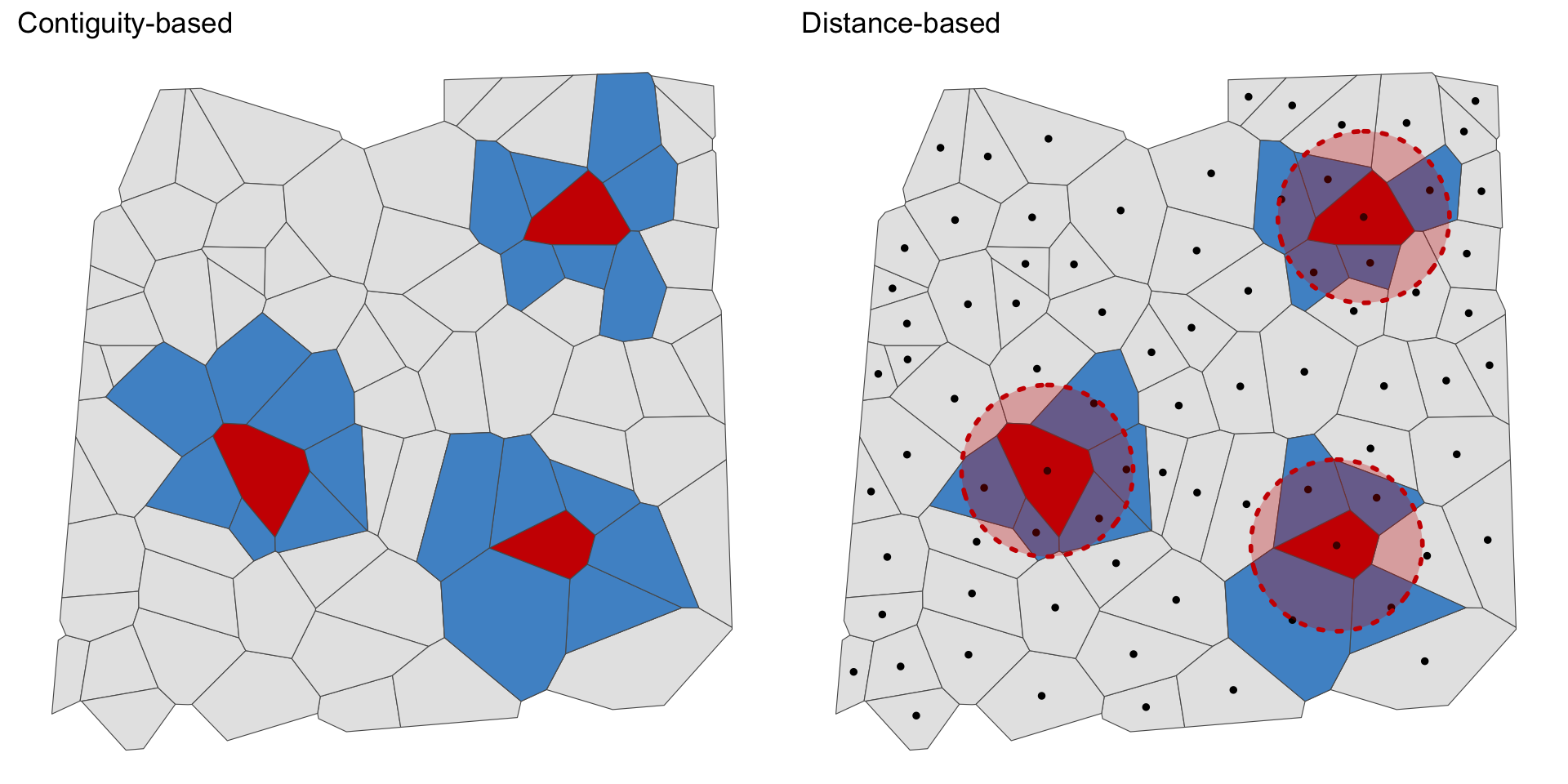
Adjacency matrix
For areal data it is quite common to implement \(W=A\) where \(A = (a_{ij})\) is an adjacency matrix with the following definition: \[ a_{ij} = \begin{cases} 1 & i \sim j \text{ where } i \neq j \\ 0 & \text{otherwise.} \end{cases} \]
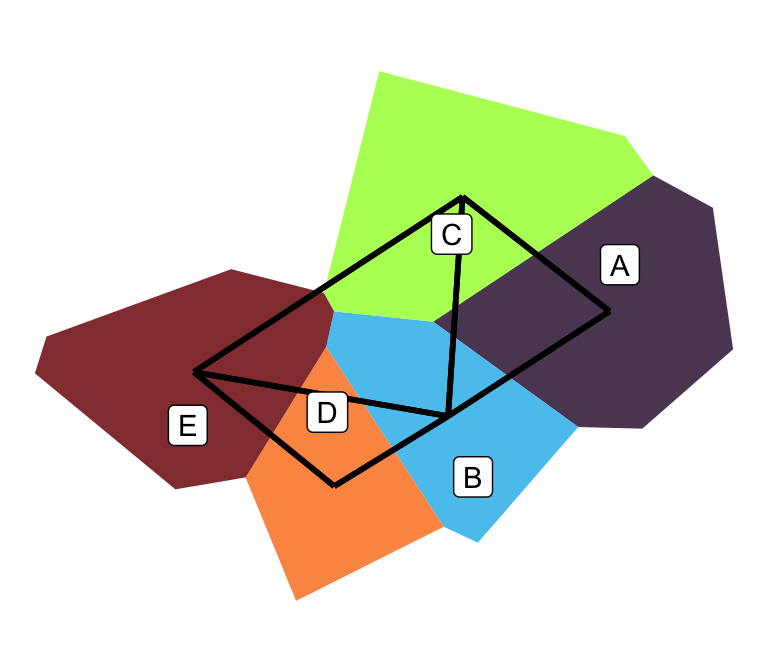
A B C D E
A 0 1 1 0 0
B 1 0 1 1 1
C 1 1 0 0 1
D 0 1 0 0 1
E 0 1 1 1 0Other useful definitions:
\(D = \operatorname{diag}(A1)\) is a diagonal matrix containing number of neighbours.
\(\tilde W = D^{-1}A\) is the scaled adjacency matrix (row sums are 1).
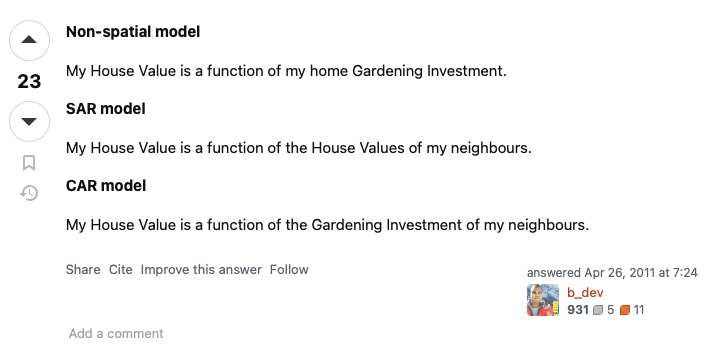
Conditionally autoregressive (CAR) priors
Let \(\psi_i=\phi_i\). Then, the CAR prior (Leroux, Lei, and Breslow 2000) is defined as \[ \phi_i \mid \phi_{-i},W,\rho,\tau^2 \sim \operatorname{N}\left(\frac{\rho\sum_{j} w_{ij} \phi_j}{\rho\sum_{j} w_{ij}+1-\rho}, \frac{\tau^2}{\rho\sum_{j} w_{ij}+1-\rho}\right), \] where \(\rho\in[0,1]\) is a spatial dependence parameter; \(\tau^2\) is a variance parameter; and \(W\) is a known weight matrix (e.g. \(W=A \in \{0,1\}^{M\times M}\) adjacency matrix).
Special cases:
- \(\rho = 0\) corresponds to independence;
- \(\rho = 1\) corresponds to the Intrinsic CAR;
- \(\rho=1\) and \(\psi_i = \phi_i + \theta_i\), where \(\theta_i\sim\operatorname{N}(0,\sigma^2)\) – this is the BYM (1991) model for binomial, Poisson and ZIP likelihoods.
Aside
Simultaneously autoregressive models
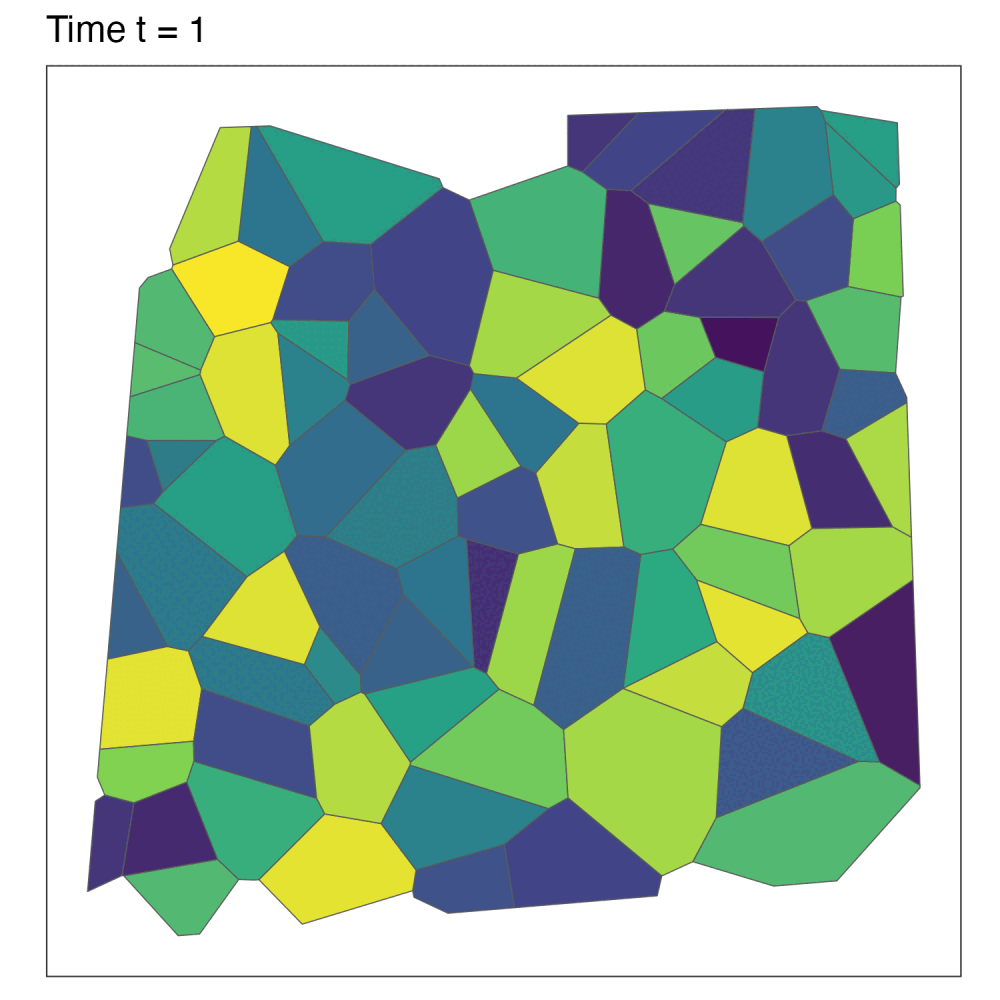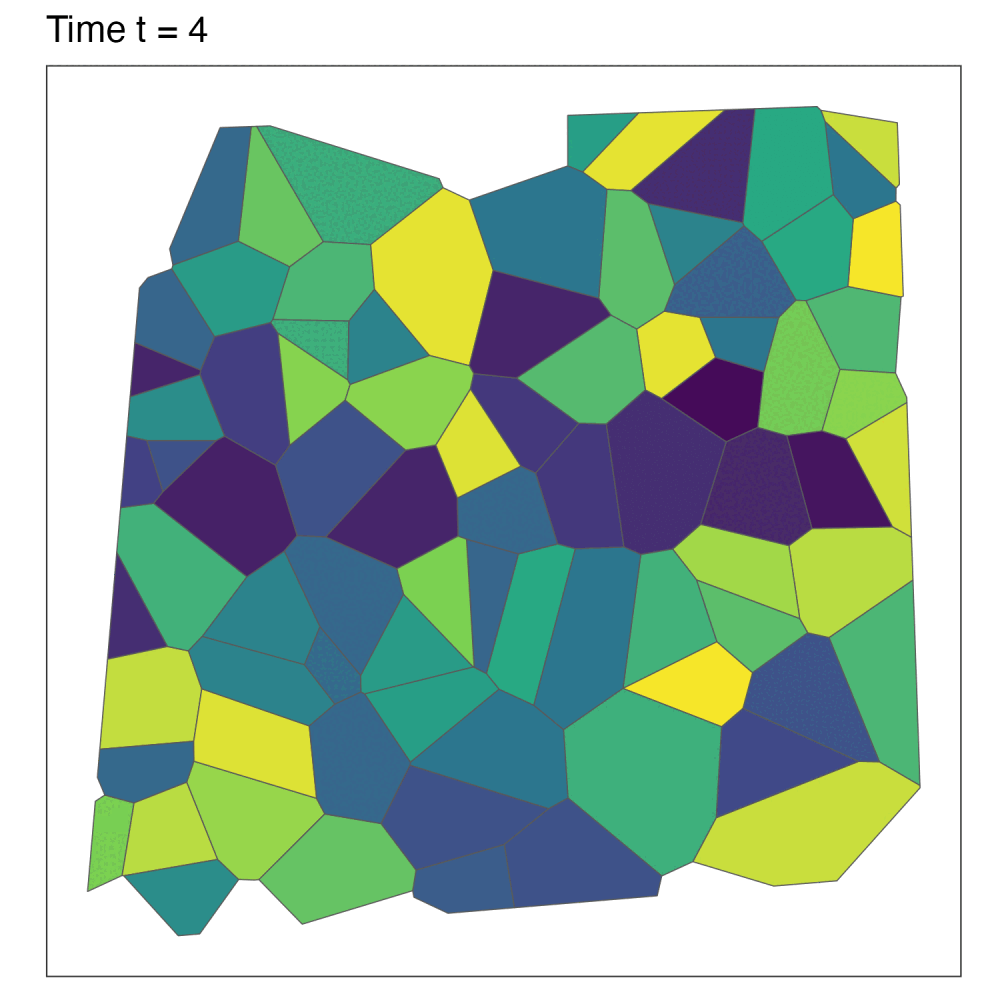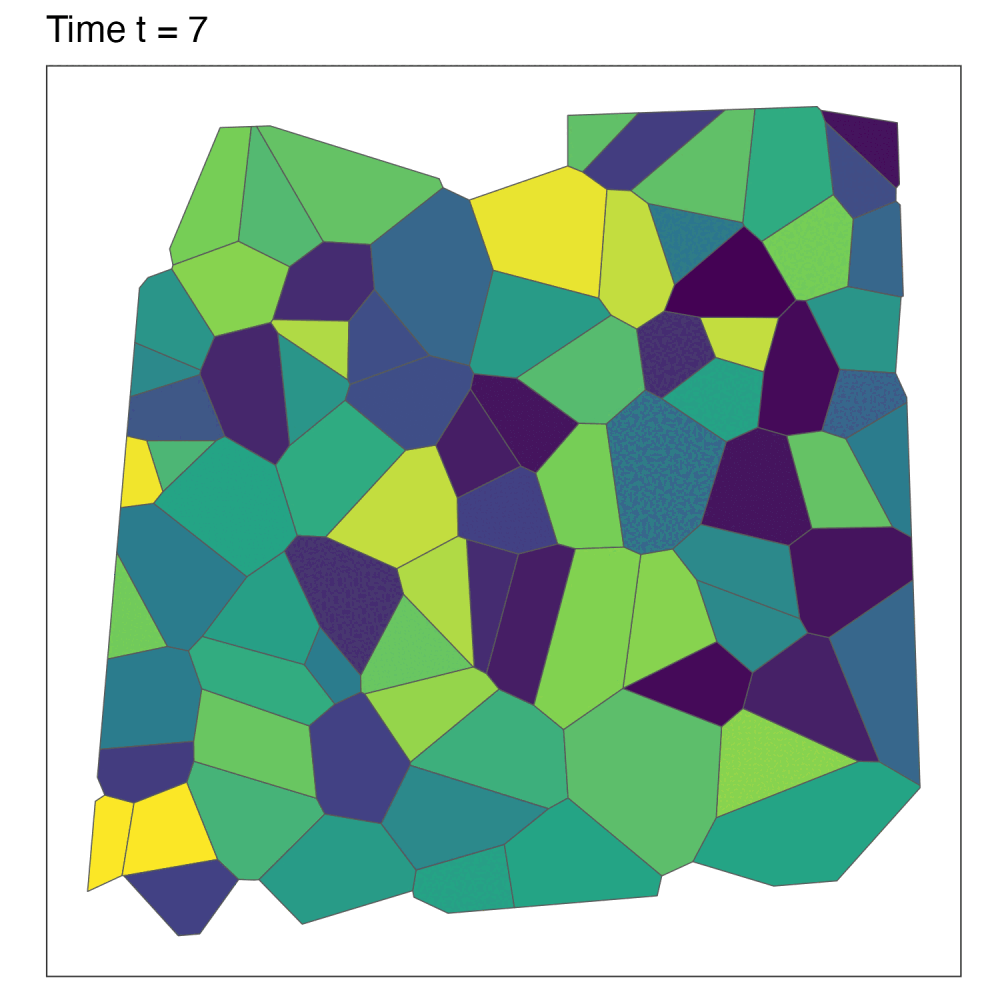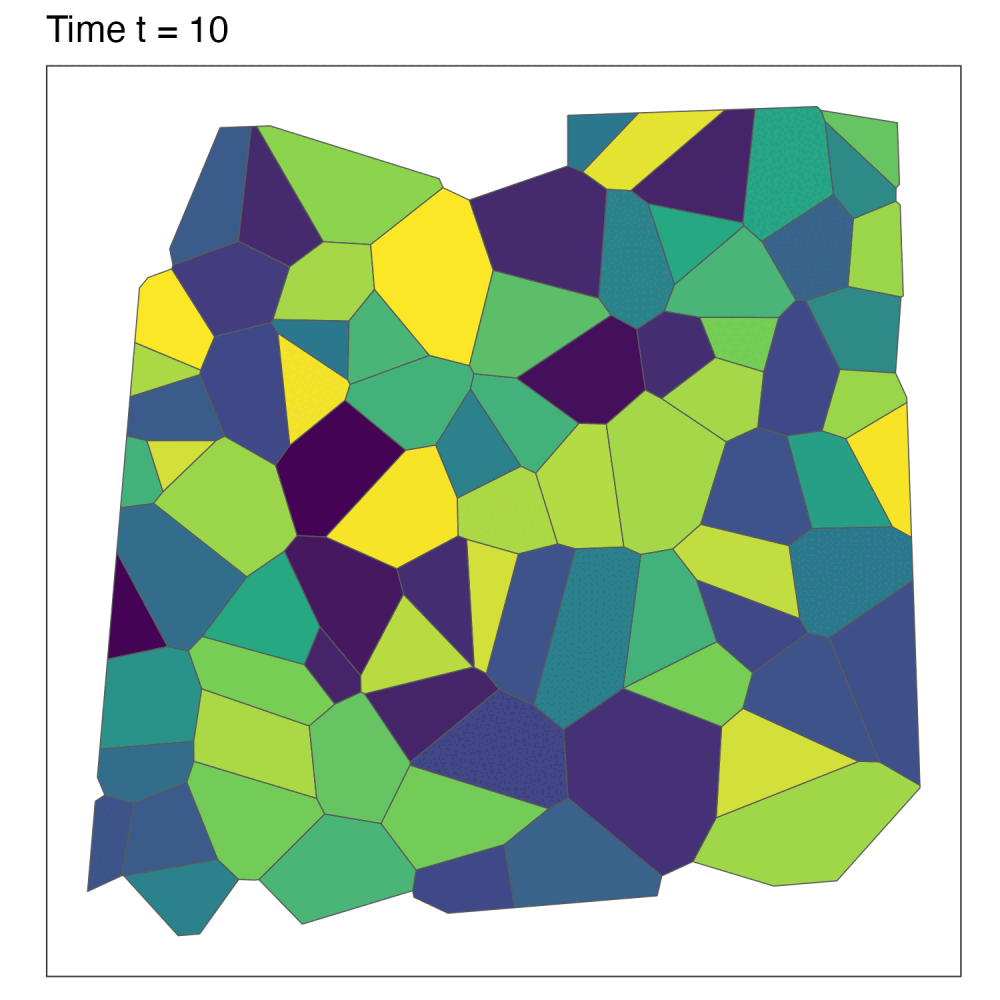
Adding the temporal element
Now suppose data at each spatial unit is recorded for \(t=1,\dots,T\) time periods. Extend the model: \[ \begin{gather} y_{it} \sim p(y_{it} \mid \mu_{it}, \nu^2) \\ g(\mu_{it}) = x_{it}^\top\beta + \psi_{it}. \end{gather} \]
We’ll discuss three ways to model the temporal dependence:
- Linear time effects
- ANOVA decomposition
- Time autoregressive process
Aggregating data and missing values
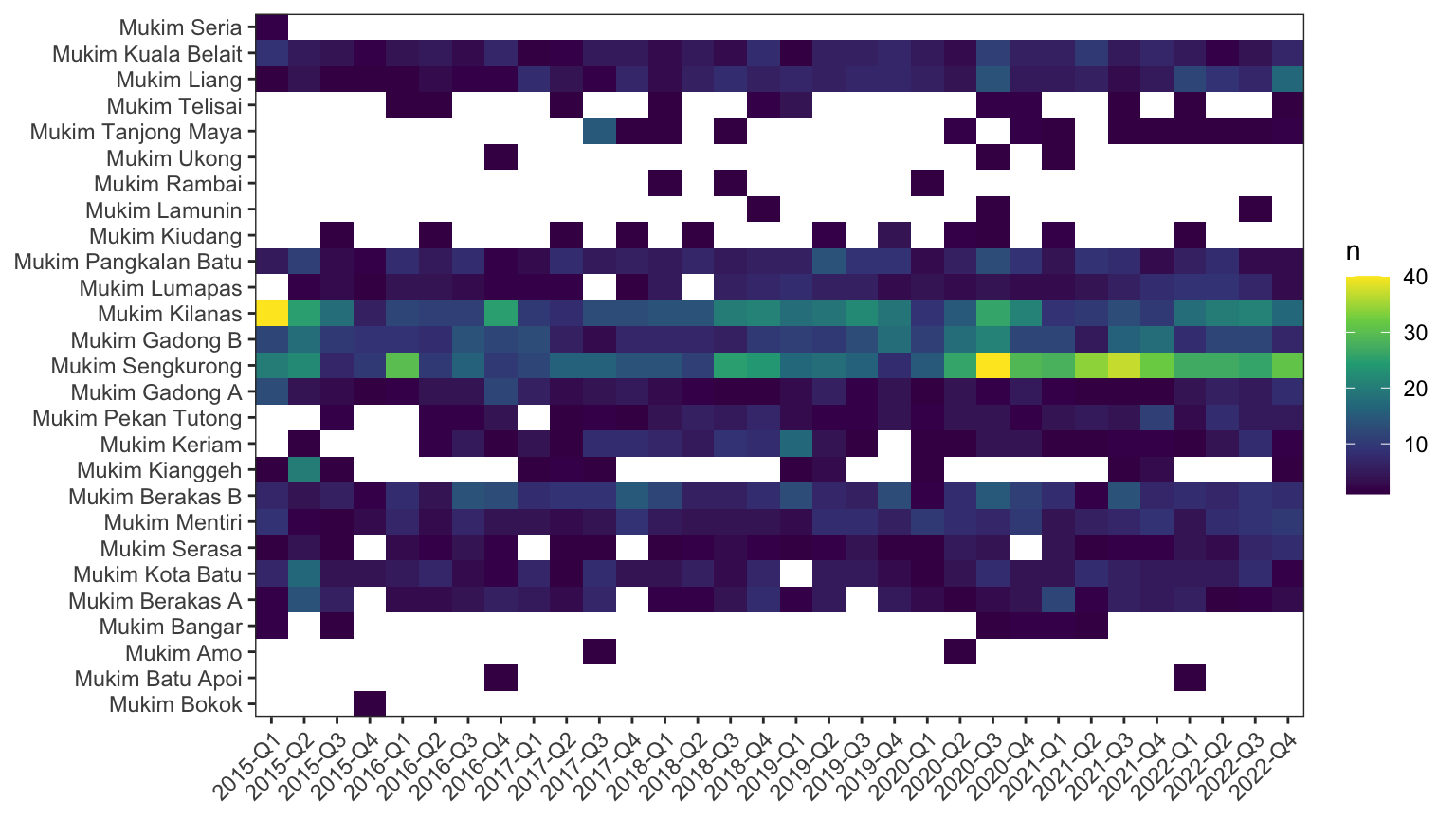
Spatio-temporal imputation
Everything is related to everything else, but near things are more related than distant things. — Tobler’s first law of geography
Strategy
- For each \(i\), find its neighbours.
- Subset data to \(i\)’s neighbours, and compute a 3-quarter rolling statistic
- For continuous variables: the mean.
- For discrete variable: the mode.
- Repeat for 1–2 for each \(i\).
- Repeat steps 1–3 using imputed data, until complete.

Validation of imputation method
Continuous variables
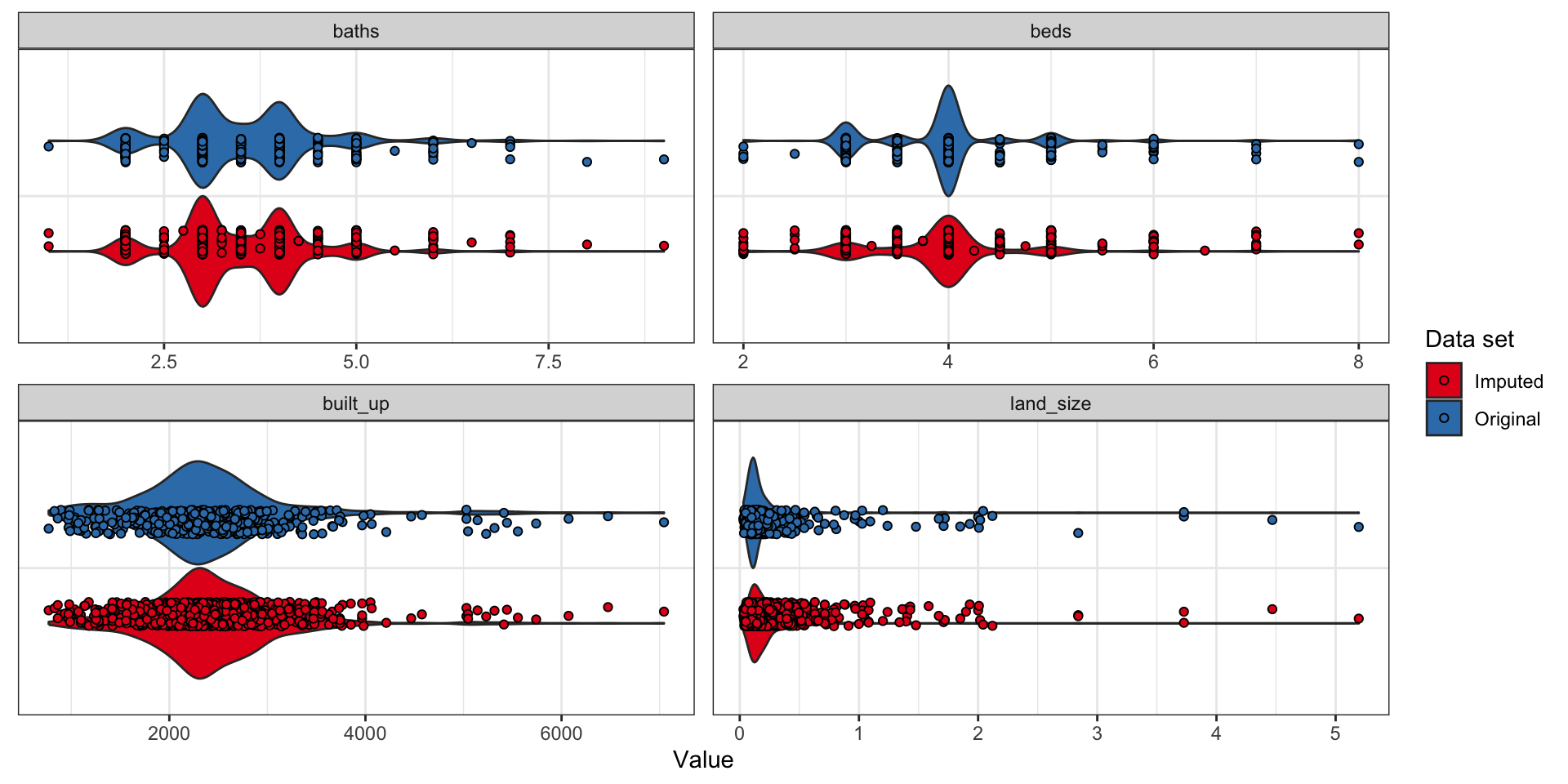
Validation of imputation method
Categorical variables
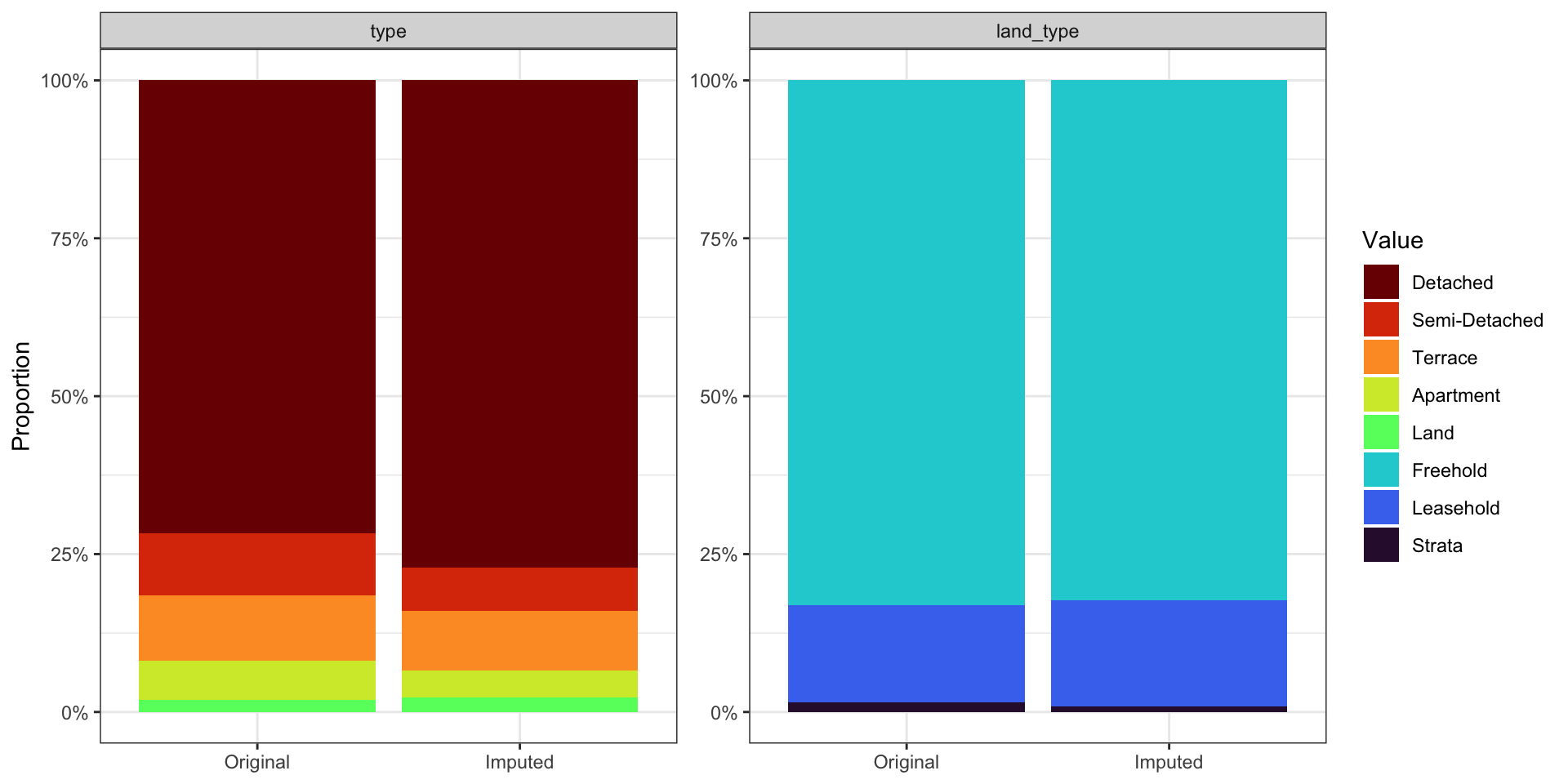
Monopoly Brunei Edition

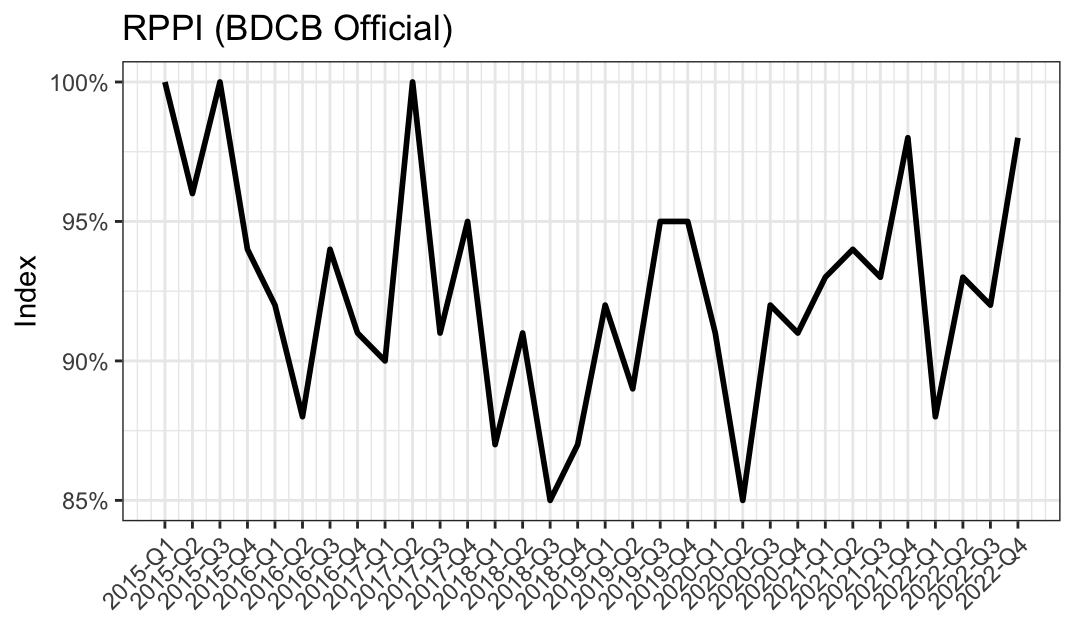
RPPI-specific research
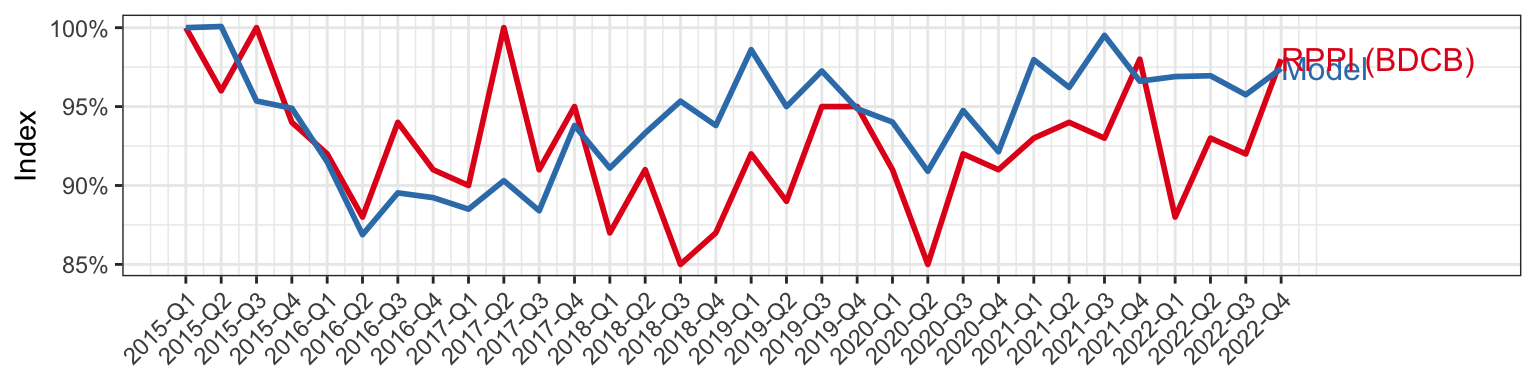
Need for time-varying regression coefficients?
- It may not make sense that the coefficients are fixed for a long period of time.
- Rolling window methods?
Building of RPPI by predicting price of an “average house” in quarter.
- Mix adjustment methods? ‘Basket of goods’ analogy for building consumer price index.
Increasing coverage
- Use advertised listings from real estate agents. Scrape online data.
References
Bernardinelli, Luisa, D Clayton, Cristiana Pascutto, Chiara Montomoli, Mauro Ghislandi, and Marco Songini. 1995. “Bayesian Analysis of Space—Time Variation in Disease Risk.” Statistics in Medicine 14 (21-22): 2433–43.
Besag, Julian. 1974. “Spatial Interaction and the Statistical Analysis of Lattice Systems.” Journal of the Royal Statistical Society: Series B (Methodological) 36 (2): 192–225.
Besag, Julian, and David Higdon. 1999. “Bayesian Analysis of Agricultural Field Experiments.” Journal of the Royal Statistical Society Series B: Statistical Methodology 61 (4): 691–746.
Besag, Julian, Jeremy York, and Annie Mollié. 1991. “Bayesian Image Restoration, with Two Applications in Spatial Statistics.” Annals of the Institute of Statistical Mathematics 43: 1–20.
Brewer, Mark J, and Andrew J Nolan. 2007. “Variable Smoothing in Bayesian Intrinsic Autoregressions.” Environmetrics: The Official Journal of the International Environmetrics Society 18 (8): 841–57.
Gavin, John, and Christopher Jennison. 1997. “A Subpixel Image Restoration Algorithm.” Journal of Computational and Graphical Statistics 6 (2): 182–201.
Knorr-Held, Leonhard. 2000. “Bayesian Modelling of Inseparable Space-Time Variation in Disease Risk.” Statistics in Medicine 19 (17-18): 2555–67.
Lee, Duncan, Alastair Rushworth, and Gary Napier. 2018. “Spatio-Temporal Areal Unit Modeling in r with Conditional Autoregressive Priors Using the CARBayesST Package.” Journal of Statistical Software 84: 1–39.
Leroux, Brian G, Xingye Lei, and Norman Breslow. 2000. “Estimation of Disease Rates in Small Areas: A New Mixed Model for Spatial Dependence.” In Statistical Models in Epidemiology, the Environment, and Clinical Trials, 179–91. Springer.
LeSage, James, and Robert Kelley Pace. 2009. Introduction to Spatial Econometrics. Chapman; Hall/CRC.
Li, Shi, Stuart Batterman, Elizabeth Wasilevich, Huda Elasaad, Robert Wahl, and Bhramar Mukherjee. 2011. “Asthma Exacerbation and Proximity of Residence to Major Roads: A Population-Based Matched Case-Control Study Among the Pediatric Medicaid Population in Detroit, Michigan.” Environmental Health 10 (1): 1–10.
Moran, Patrick AP. 1948. “The Interpretation of Statistical Maps.” Journal of the Royal Statistical Society. Series B (Methodological) 10 (2): 243–51.
Pebesma, Edzer, and Roger Bivand. 2023. Spatial Data Science: With applications in R. Chapman and Hall/CRC. https://doi.org/10.1201/9780429459016.
Rushworth, Alastair, Duncan Lee, and Richard Mitchell. 2014. “A Spatio-Temporal Model for Estimating the Long-Term Effects of Air Pollution on Respiratory Hospital Admissions in Greater London.” Spatial and Spatio-Temporal Epidemiology 10: 29–38.
Spiegelhalter, David J, Nicola G Best, Bradley P Carlin, and Angelika Van Der Linde. 2002. “Bayesian Measures of Model Complexity and Fit.” Journal of the Royal Statistical Society Series B: Statistical Methodology 64 (4): 583–639.
Wall, Melanie M. 2004. “A Close Look at the Spatial Structure Implied by the CAR and SAR Models.” Journal of Statistical Planning and Inference 121 (2): 311–24.
Watanabe, Sumio, and Manfred Opper. 2010. “Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory.” Journal of Machine Learning Research 11 (12).
Xie, Sherrie, Rebecca Greenblatt, Michael Z Levy, and Blanca E Himes. 2017. “Enhancing Electronic Health Record Data with Geospatial Information.” AMIA Summits on Translational Science Proceedings 2017: 123.